
티스토리 뷰
안녕하세요 Pingu입니다.🐧
저난 글에서는 파일 시스템 중 Log-Structed File System(LFS)에 대해 알아봤었는데요, 이번 글에서는 요즘 많이 사용하는 Flash 기반 SSD에 대해 알아보려고 합니다! Flash 기반 SSD에는 LFS의 아이디어를 사용한다고 하는데요, 요즘 많이 사용하니까 좀 더 궁금하기도 하고 빨리 알아보도록 하겠습니다. 제가 공부할 때 참고하고 있는 책인 OSTEP에서는 Chapter 44 - Flash-based SSDs 부분 입니다!
Flash-based SSDs
하드 디스크 드라이브만을 사용하다가 최근 새로운 형태의 저장 장치가 생겨났죠? 바로 Solid States Storage device(SSD)라고 하는 장치인데요, 하드 드라이브와는 다르게 데이터를 탐색할 때 모터가 존재하지 않습니다. 대신 메모리나 프로세서와 같이 트랜지스터로 구성되는데요, 메모리와는 다르게 SSD는 전원이 꺼지더라도 데이터를 유지하기 때문에 하드 디스크를 대신하여 사용할 수 있습니다.
이러한 SSD는 1980년대 만들어진 Flash(NAND 기반 Flash)에서 시작됩니다. 플래시는 몇 가지 특성들이 있는데요, 어떤 데이터를 쓸 때 해당 데이터가 속해있는 부분을 모두 지웠다가 새로 써야 하기 때문에 성능이 상당히 나쁠 수 있습니다. 또한 이렇게 자주 뭔갈 쓰고 지우고 하다 보면 플래시 메모리는 쓸 수 없게 됩니다. 이러한 특성 중 뭔갈 쓸 때 지워야 하는 특성과 너무 자주 지우고 쓰기를 반복하면 마모되는 특성을 보완한 것이 SSD라고 할 수 있습니다.
Storing a Single Bit
플래시 칩은 단일 트랜지스터에 하나 이상의 비트를 저장하도록 설계되었습니다. 비트는 0, 1의 값을 가질 수 있으며 Single-level cell 플래시의 경우 하나의 트랜지스터에 하나의 비트만 저장됩니다. Multi-level cell을 사용하면 2개의 비트가 서로 다른 전하 레벨로 인코딩 되고 한 셀당 3개의 비트를 인코딩하는 Triple-level cell 플래시도 있다고 합니다.
From Bits to Banks / Planes
플래시 칩은 방금 알아본 cell들이 여러 개 들어있는 bank 혹은 plane으로 구성됩니다. Bank는 메모리 접근을 두 개의 단위로 접근하는데, 일반적으로 128KB, 256KB 크기의 block과 4KB 정도의 작은 page 단위가 있습니다. 여기서 플래시의 block, page는 기존에 공부한 디스크의 block과 메모리에서의 page와는 다릅니다.
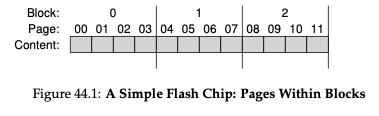
위의 그림은 블록과 페이지가 있는 플래시 plane의 예입니다. 위의 그림에서는 3개의 block이 있고 각 블록에는 4개의 page가 있는 것을 볼 수 있습니다. 그럼 왜 이렇게 블록과 페이지로 접근 단위를 구분하는 것일까요? 아까 플래시는 뭔갈 쓰려면 지워야 한다고 했습니다. 이때 page 단위를 쓰려고 한다면 해당 page가 속해있는 block을 모두 지워버려야 한다는 것인데... 뭔가 매우 비효율적으로 보입니다. 이러한 특성으로 인해 플래시 기반 SSD를 만드는 것은 어려운 도전이며 이는 글 마지막 부분에서 알아보도록 하겠습니다.
Basic Flash Operations
지금까지 알아본 플래시 칩은 세 가지 작업을 지원해야 하는 것을 알 수 있습니다. Read, Write, Erase가 그 세 가지 작업이죠. 그럼 세 가지 작업을 좀 더 자세히 알아볼까요?
- Read (page단위) : 플래시 칩의 클라이언트는 읽기 명령과 적절한 Page 번호를 디바이스에 지정하기만 하면 모든 페이지를 읽을 수 있습니다. 읽기 작업은 위치와 상관없이 10ms 정도로 매우 빠르며 하드 디스크와는 다르게 이전 요청의 위치와 관계없는 성능을 보입니다. 모든 위치에서 균일한 성능을 낼 수 있다는 점에서 플래시 칩은 random access device라고 할 수 있습니다.
- Erase (Block 단위) : 플래시 내의 페이지에 쓰기 전에 디바이스 특성상 페이지가 있는 전체 블록을 먼저 지워야 합니다. Erase는 블록의 내용 전체를 지우기 때문에 수행하기 전에 해당 블록에 뭔가 필요한 정보가 있는지를 확인하고 해당 정보가 복사되어있는지를 확인해야 합니다. Erase 명령은 비용이 많이 들고 완료하는데 ms초 단위가 걸리게 됩니다. Erase 명령이 완료되면 전체 블록이 재설정되고 각 페이지를 프로그래밍할 준비가 됩니다.
- Program (Page 단위) : 플래시 칩에서는 Write 명령을 Program이라고 부릅니다. 블록이 삭제되면 프로그램 명령을 사용하여 페이지의 1 중에 일부를 0으로 변경하고 원하는 페이지 내용을 플래시에 쓸 수 있습니다. 페이지를 Program 하는 것은 Erase 하는 것보다는 비용이 적게 들지만 페이지를 읽는 것 보다는 비용이 많이 들고 일반적으로는 100ms 정도가 걸립니다.
플래시 칩에서 생각해야 하는 점은 페이지마다 상태가 존재한다는 것입니다. 제일 처음엔 INVALID 상태로 시작되며 해당 페이지가 존재하는 블록을 지우면 ERASED 상태가 됩니다. Program 명령을 수행하면 페이지의 상태는 VALID 상태가 됩니다. 이는 해당 페이지에 뭔가 쓰였으며 읽을 수 있는 상태임을 나타내게 됩니다. 당연하겠지만 Read 명령은 페이지의 상태에 영향을 주지 않습니다. 하나의 페이지가 Program 되었다면 수정하는 방법은 Erase를 한 뒤 다른 곳에 다시 Program 하는 방법인데요, 플래시 칩의 3가지 명령어가 수행되는 과정을 예를 보며 이해해보겠습니다!
A Detailed Example
플래시 칩에서는 쓰기 작업이 기존의 하드 디스크와는 많이 다른 것을 알 수 있었는데요, 기존에는 그냥 덮어쓰면 됐지만 지금은 해당 페이지가 속한 블록을 모두 삭제해야 하는 어떻게 보면 너무나도 비효율적인 방법으로 진행됩니다. 그럼 간단하게 블록의 크기가 4페이지이고 페이지의 크기는 8비트인 플래시 칩으로 명령들이 어떻게 수행되는지 살펴보도록 하겠습니다.

위의 그림을 보면 네 개의 페이지가 모두 VALID 상태인 것을 볼 수 있고 이는 뭔가가 쓰인 상태라는 것을 알 수 있습니다. 이러한 상황에서 Page 0에 뭔가를 수정하고 싶을 땐 어떻게 될까요?

어떤 페이지를 수정하려면 해당 페이지가 속해있는 블록을 모두 지워야 한다고 했었죠? 그래서 위와 같이 모든 페이지를 모두 ERASED 상태로 지워줘야 합니다. 이렇게 된다면 Page 0에는 새로운 데이터를 수정할 수 있겠네요.

그래서 위와 같이 Page 0에 뭔갈 수정했다고 해보겠습니다. 처음 원했던 작업인 Page 0은 수정이 됐지만 가만히 있던 Page 1,2,3이 모두 지워진 상태가 되었습니다. ??? Page 1,2,3은 지워지고 싶지도 않았는데 지워진 상태가 된 것입니다. 따라서 이런 문제를 발생하지 않기 위해 블록을 지우기 전에 해당 블록의 다른 페이지들은 다른 위치로 옮겨줘야 합니다. 즉 복사를 해줘야 한다는 것이죠. 이러한 Erase 특징은 Flash based SSD를 설계하는데 큰 영향을 끼치게 됩니다.
Summary
플래시 칩의 3가지 명령을 정리해보면, Read 작업은 그냥 읽으면 되니까 정말 간단합니다. 기존의 하드 디스크와는 다르게 어떤 위치에 접근하더라도 성능이 좋기 때문에 아주 좋다고 할 수 있죠.
근데 문제는 페이지를 Write 할 때 발생합니다. 아까 예에서 봤듯 어떤 페이지를 수정하기 위해서는 해당 페이지가 속한 블록을 모두 지워버리기 때문에 블록 내의 다른 페이지는 복사를 해줘야 하는 새로운 일이 생겨나게 됩니다. 또한 플래시 칩은 많이 사용하면 마모가 되는데, Program / Erase 작업을 자주 하게 되면 수명이 빨리 닳을 수 있습니다. 근데 이렇게 쓰기 작업을 할 때 복잡한데도 불구하고 도대체 플래시는 왜 써야 하는 걸까요? 이에 대한 것들을 지금부터 알아보도록 하겠습니다.
Flash Performance And Reliablity

이번에는 플래시 칩의 성능을 한 번 알아보도록 하겠습니다. 위의 그림은 SLC(Single Level Cell), MLC(Multi Level Cell), TLC(Triple Level Cell) 플래시에서 Read, Program, Erase 작업에 대한 수행 시간을 나타낸 표입니다. 표에서 볼 수 있듯 읽기 작업은 매우 성능이 좋은 것을 알 수 있으며 Program 작업의 경우에는 Single Level의 경우 200ms이며 셀에 비트를 더 많이 넣을수록 시간은 늘어납니다. 그리고 Erase 작업의 경우 다른 작업에 비해 시간이 많이 걸리는 것을 볼 수 있습니다. 따라서 Flash Storage는 Erase 작업을 처리하는 것에 많은 노력을 합니다.
그럼 플래시 칩의 Reliability(신뢰성)은 어떨까요? 플래시 칩은 실리콘으로 되어있고 이에 따라 신뢰성 문제가 적습니다. 하지만 마모는 될 수 있죠. 플래시 블록을 썼다 지웠다를 반복하게 되면 점점 마모가 되며 언젠간 블록을 사용하지 못하게 됩니다. 블록의 수명은 MLC 기반 블록이 10000번의 쓰고 지우기를 할 수 있으며 SLC 기반 칩은 10만 번의 쓰고 지우기를 할 수 있습니다.
플래시 칩의 신뢰성 문제에는 disturbance(교란)도 있습니다. 플래시 내의 특정 페이지에 접근할 때 근처에 있는 페이지의 일부 비트에 영향을 줄 수도 있습니다. 이러한 bit flips는 페이지를 각각 읽거나 프로그래밍 중인지 여부에 따라 read disturb, program disturb로 나눌 수 있습니다.
From Raw Flash to Flash-Based SSDs
이제 플래시 칩을 어느 정도 이해했으니 이를 SSD로 만들어야 합니다. 즉 플래시 칩을 저장장치처럼 보이도록 해야 하는데요, 표준 스토리지 인터페이스는 블록 주소가 주어지면 512 바이트 크기의 블록을 읽거나 쓸 수 있는 단순한 블록 기반 인터페이스입니다. 플래시 기반 SSD의 임무는 내부의 플래시 칩 위에 표준 블록 인터페이스를 제공하는 것입니다. 즉 쉽게 말해서 플래시 칩을 표준 스토리지 인터페이스에 적합하도록 만들어줘야 하죠.
내부적으로 SSD는 몇 개의 플래시 칩으로 구성되고 일정량의 휘발성 메모리를 포함합니다. 이러한 메모리는 데이터 캐싱, 버퍼링, 테이블 매핑에 사용하게 되며 이는 조금 뒤에 알아보도록 하겠습니다.

마지막으로 SSD에는 장치 작동을 조율하기 위한 제어 로직이 포함되어 있으며 이는 위의 그림과 같이 단순화할 수 있습니다. 위의 그림과 같은 제어 로직의 필수 기능 중 하나는 클라이언트 읽기 및 쓰기를 수행하여 필요에 따라 내부 플래시 작업으로 전환하는 것입니다. Flash Translation Layer(FTL)는 이러한 기능을 제공합니다. FTL은 논리 블록에 대한 읽기, 쓰기 요청을 가져와 기본 물리적 블록 및 물리적 페이지에서 low-level read, erase, program 명령어로 변환합니다.
이러한 작업들은 여러 가지 기술의 조합으로 실현될 수 있는데요, 핵심은 플래시 칩을 병렬로 활용한다는 것입니다. 실제로 SSD에는 여러 개의 플래시 칩을 사용합니다. 그리고 아까도 봤듯 write 작업이 오래 걸린다는 점을 해결해야 합니다.
신뢰성의 경우에는 크게 문제가 되지 않지만 플래시 칩의 문제는 wear out(마모)이었습니다. 블록을 자주 지웠다 쓰게 되면 점점 마모가 되었고 언젠간 이를 사용할 수 없게 되었습니다. 따라서 FTL은 플래시 블록에 쓸 때 최대한 균등하게 분산하여 메모리를 사용하도록 만들어야 하고 이를 wear leveling이라고 하며 FTL의 필수 부분이라고 할 수 있습니다.
또 다른 신뢰성 문제는 program disturbance인데요, 이러한 방해를 최소화하기 위해 FTL은 일반적으로 낮은 페이지에서 높은 페이지의 순서로 지워진 블록의 페이지를 프로그래밍합니다. 이렇게 순차적으로 접근하게 되면 disturbance를 줄일 수 있다고 합니다.
FTL Organization: A Bad Approach
읽기 및 쓰기 작업을 플래시 작업으로 변환해주는 게 FTL이라고 했었는데요, 이러한 FTL를 가장 간단하게 만들 수 있는 구조는 direct mapped (직접 매핑)입니다. 이 방법은 논리적 페이지 N에 대한 읽기는 물리적 페이지 N의 읽기에 직접 매핑되는 방법을 말합니다. 논리적 페이지 N에 대한 쓰기는 좀 더 복잡한데요, 플래시는 어떤 페이지에 쓰기 작업을 할 때 포함된 블록을 지워야 하기 때문에 FTL은 N이 포함된 블록을 읽고 해당 블록을 지웁니다. 마지막으로 FTL은 이전 페이지와 새로운 페이지를 프로그래밍합니다.
이러한 direct mapped FTL은 성능과 안정성 측면에서 별로라는 생각이 들 텐데요, 성능 문제는 쓰기 문제에서 발생합니다. 전체 블록을 읽고 블록을 지운 뒤 다시 써야 하기 때문에 하나의 페이지를 수정하는데도 해당 페이지가 속한 블록을 모두 써야 하는 비효율적인 방법입니다. 이러한 방법은 seek time, rotate time이 있는 일반 하드 디스크보다도 느리다고 할 수 있습니다.
성능뿐만 아니라 이러한 방법은 신뢰성도 매우 나쁜데요, 파일 시스템의 메타 데이터와 사용자의 데이터를 계속해서 지웠다가 쓰게 되면 플래시 칩이 마모됩니다. 따라서 이러한 direct mapped 구조의 FTL은 별로 좋지 않습니다.
A Log-Structured FTL
그럼 FTL을 어떻게 만들어야 할까요? 많은 FTL은 log-structured로 되어있으며 저장 장치와 파일 시스템 모두에게 유용한 아이디어입니다. Log strucure File System(LFS)는 지난 글에서 알아봤었는데요, 간단히 말하면 쓰기 작업을 늘 새로운 공간에 연속적으로 하여 성능을 좋게 만들자는 아이디어였습니다. 이를 플래시 칩의 입장에서 살펴보면 어떤 페이지를 수정하고 싶어서 해당 페이지가 속한 블록을 모두 지우는 것이 아닌 빈 공간에서 새로운 정보로 다시 쓰게 됩니다. 이러한 방법을 logging이라고 하며 이렇게 쓰인 블록의 순서를 알기 위해 mapping table을 가지게 됩니다. Mapping table은 시스템에 있는 블록들의 물리적 주소를 저장하는데요, 이러한 과정을 자세히 살펴보며 이해해보도록 하겠습니다.
어떤 SSD가 존재하며 이는 512 바이트 섹터를 읽고 쓸 수 있는 디스크처럼 사용할 수 있게 만들어졌다고 가정해보겠습니다. 파일 시스템은 이를 4KB 크기의 chunk를 읽거나 쓰고 있다고 가정하며 하나의 블록은 4KB 페이지 4개로 구성되었다고 생각해보겠습니다. 이러한 SSD로 파일 시스템이 다음과 같은 작업을 수행한다면 어떻게 될까요?
- 100번 주소에 a1을 쓰기
- 101번 주소에 a1를 쓰기
- 2000번 주소에 b1을 쓰기
- 2001번 주소에 b2를 쓰기
위에서 주소 번호는 SSD의 파일 시스템이 정보가 있는 위치를 기억하는 데 사용됩니다.
이러한 작업을 수행하기 위해서 내부적으로는 쓰기 작업을 Erase, Program 작업으로 변환하고 SSD의 논리 블록 주소에 저장해야 합니다. SSD의 모든 블록이 현재 유효하지 않으며 페이지를 program 하기 전에 erase 해야 한다고 가정한다면 아래와 같은 상태일 거예요.

위의 그림에서 State에 i는 INVALID 상태를 나타냅니다. 아까 수행한다고 한 4개의 작업 중 첫 번째 작업을 먼저 수행해볼까요? 첫 번째 쓰기인 100번 주소에 a1을 쓰기 작업이 SSD에 들어오면 FTL은 0,1,2,3 페이지를 포함하는 블록 0번에 쓰기로 결정합니다. 해당 블록을 보면 모든 페이지가 INVALID 하기 때문에 아직은 쓸 수 없기 때문에 ERASE 명령을 먼저 수행해줘야 합니다.

ERASE 작업을 해주면 위의 그림과 같이 State가 ERASED로 바뀌게 되고 뭔가를 쓸 수 있는 상태가 됩니다. 따라서 아까 들어온 작업인 a1을 물리적 페이지 0번에 보냅니다.
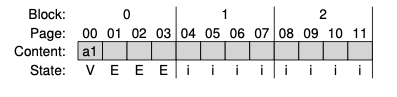
이렇게만 하게 되면 파일 시스템이 a1이 저장된 논리 블록 100을 읽을 수가 없겠죠? 그래서 아까 언급한 mapping table을 만들어줘야 합니다. Mapping table로 논리적 읽기 100번을 물리적 페이지 0을 읽는 작업으로 변환해줘야 하는 것이죠. 이를 위해 mapping table에 이러한 정보를 저장해주면 아래와 같아집니다.

이제 파일 시스템이 SSD에 뭔가를 쓸 때 어떤 일이 발생하는지 볼 수 있습니다. SSD는 쓰기 위한 위치를 찾습니다. 일반적으로 빈 페이지를 선택하게 되며 블록의 내용으로 해당 페이지를 progamming 하고 mapping table에 이를 기록합니다. 이렇게 나머지 세 개의 작업인 101, 2000, 2001을 쓰게 되면 아래와 같아집니다.

이렇게 log structured 방법은 ERASE 작업을 줄이고 direct mapping 방법의 복잡한 쓰기 방법이 아닌 간단하게 쓰기 작업을 수행하여 성능과 안정성을 향상합니다. FTL은 모든 페이지에 쓰기를 분산하여 ware leveling(데이터를 골고루 분산시키는 것)을 수행하여 마모를 최대한 적게 발생시킬 수 있습니다. Ware leveling에 대한 것은 곧 다시 알아보도록 하겠습니다.
하지만 늘 그랬듯 이러한 log structured 방법에도 단점이 있습니다. 첫 번째는 논리 블록을 덮어쓰면 garbage가 발생하고 이러한 garbage는 사용하지도 않는데 공간을 차지하게 됩니다. 디바이스는 여유 공간을 확보하기 위해 주기적으로 garbage collection을 수행해야 하며 이것 역시 너무 자주 수행하면 성능 저하를 발생하므로 적절히 수행해줘야 합니다. 두 번째는 mapping table의 높은 비용입니다. SSD의 크기가 커질 수록 mapping table의 크기도 커지기 때문에 이를 적절히 처리해줘야될 것 같아요.
Garbage Collection
방금 알아본 대로 log-structured 방법은 garbage가 생성되기 때문에 이를 처리할 garbage collection을 수행해줘야합니다. 아까의 예를 이어서 살펴보도록 하겠습니다. 아까 예의 마지막 상황은 논리 블록 100, 101, 2000, 2001이 저장된 상태였습니다. 이 상태에서 블록 100, 101에 적힌 a1, a2가 c1, c2로 수정되는 작업을 수행한다고 생각해보겠습니다. 쓰기는 다음 페이지에 쓰일 것이며 mapping table도 적절히 업데이트되겠죠? 물론 이러한 작업을 하기 위해서는 블록 1을 먼저 지워줘야 합니다.

작업을 모두 수행하면 위와 같은 상태가 될 텐데요, 현재 페이지 0, 1에 존재하는 정보는 이제 garbage가 된 것을 볼 수 있습니다. 필요 없는 데이터로 인해 낭비가 되는 상황이므로 이를 나중에 처리해줘야하며 이러한 작업을 garbage collection 이라고 합니다. 방법은 간단합니다. 블록에 하나라도 garbage 페이지가 존재한다면 해당 블록에서 유효한 페이지를 읽고 로그에 기록한 뒤 블록 전체를 지웁니다.
그럼 방금까지의 상황에서 필요없는 페이지는 0, 1이며 이를 지우는 과정을 살펴보도록 하겠습니다. 페이지 0, 1이 속해있는 블록은 0번 블록이므로 해당 블록에 존재하는 유효한 페이지를 읽어줍니다. 현재 2, 3번 페이지가 유효한 페이지이므로 2, 3페이지를 읽고 log에 씁니다. 그런 뒤 블록 0 전체를 Erase 합니다. 이때 어떤 페이지가 유효한지를 알기 위해서는 mapping table을 활용하면 됩니다. 이렇게 garbage collection을 수행하면 아래와 같은 상태가 됩니다.
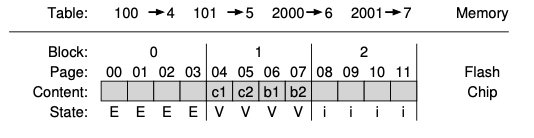
이렇게 garbage collection의 과정을 살펴봤는데 어떤가요? 데이터를 읽고, 쓰고 지우고... 엄청 복잡합니다. 가장 이상적인 상황은 하나의 블록이 모두 garbage 페이지로 구성되어 그냥 지워버리는 작업만 수행하면 되는 상황인데요, SSD는 이러한 Garbage collection의 비용을 줄이기 위해 플래시 용량을 늘려서 장치를 overprovision(오버 프로비전)을 하고 garbage collection을 나중에 할 수 있습니다. 플래시 용량이 많이 증가하게 되면 내부 대역폭이 증가하여 garbage collection에 사용할 수 있기 때문에 파일 시스템에 인식된 대역폭이 감소하지 않습니다. 최신 SSD는 이러한 방식으로 overprovision 되며 좋은 성능을 위한 핵심입니다.
Mapping Table Size
그럼 아까 알아본 log-structured 방법의 문제점 중 하나인 garbage 처리 문제는 해결했으니 이번엔 두 번째 문제였던 mapping table의 크기에 대해 알아보도록 하겠습니다. 만약 1TB SSD의 페이지 단위가 4KB라면 단순하게 만든 mapping table를 사용한다면 1GB의 메모리를 필요로 합니다. 따라서 뭔가 크기를 줄일 방법이 필요하게 됩니다.
Block-Based Mapping
Mapping 비용을 줄이기 위한 방법에는 page 마다 포인터를 유지하는 것이 아닌 블록단위로 포인터를 유지하여 매핑 정보의 양 자체를 줄이는 방법이 있습니다. 이러한 블록 레벨 FTL은 가상 메모리 시스템에서 page 크기를 키우면 페이지 테이블의 크기가 줄어들던 것과 비슷한 효과를 볼 수 있습니다. 하지만 이러한 방법은 잘 작동하지 않는데요, 가장 큰 문제는 small write에서 발생합니다. 작은 쓰기가 발생하면 블록 레벨 FTL은 블록단위의 포인터만 갖고 있기 때문에 작은 쓰기가 수행될 위치의 블록을 읽고 복사해줘야 합니다. 작은 쓰기만 하면 되는데 불필요하게 일이 커지게 되죠.

위의 그림은 블록 단위 포인터만 가진 플래시 칩의 구조입니다. a, b, c, d의 4개의 페이지가 존재하지만 이는 모두 chunk 번호 500을 가집니다. 따라서 mapping table에는 500->4 만 존재하는 것을 볼 수 있습니다. 이렇게 블록 단위로 나타내게 되면 주소 공간이 chunk 단위로 분할되며 논리 블록 주소는 chunk 번호와 offset으로 구성됩니다.
이러한 블록 기반 FTL은 읽기 작업은 쉽습니다. 먼저 FTL은 주소에서 최상위 비트를 가져와서 파일 시스템이 제시한 논리 블록 주소에서 chunk 번호를 추출합니다. 해당 chunk 번호를 mapping table에서 조회하고 해당 위치에 offset을 추가하여 원하는 페이지의 주소를 얻습니다. 만약 위의 예에서 c 페이지만 수정하고 싶다면 아래와 같이 구조가 바뀌게 됩니다.

위와 같이 블록에 속해있는 4개의 페이지 중 1개의 페이지만 수정하고 싶은데도 불구하고 블록 전체를 읽고 이를 새로운 위치에 쓰는 작업을 수행해줘야 합니다. 즉 이러한 방법은 비효율적이며 더 나은 방법은 없는지 알아봐야겠어요.
Hybrid Mapping
방금 본 블록 기반 FTL은 매핑 테이블의 크기는 줄일 수 있지만 추가적인 작업으로 인한 오버헤드가 발생하여 특히 작은 쓰기에 대해 성능이 별로였습니다. 이를 보완하기 위한 방법으로 FTL은 Hybrid mapping 기술을 사용하는데요, 이 방법은 FTL이 몇 개의 블록을 지우고 모든 쓰기를 해당 블록으로 보냅니다. 이를 log 블록이라고 하며 FTL은 모든 블록을 복사하는 것이 아닌 log 블록에 페이지를 쓸 수 있기 때문에 log 블록에 대한 페이지 매핑을 유지합니다.
즉 하이브리드 방법은 매핑 테이블이 2개가 되는 것인데요, 하나는 log table이라고 하는 페이지당 매핑 정보이고 data table이라고 하는 블록 당 매핑 정보 테이블이 있습니다. 특정 논리 블록을 찾을 때 FTL은 log table을 먼저 참조하여 만약 원하는 위치를 찾지 못한다면 data table을 참조하여 위치를 찾아 작업을 수행합니다.
이러한 하이브리드 매핑 전략의 핵심은 log 블록수를 적게 유지하는 것입니다. Log 블록 수를 적게 유지하려면 FTL이 log 블록을 정기적으로 검사하고 단일 블록 포인터로만 가리킬 수 있는 블록으로 전환해야 합니다. 이러한 전환은 세 가지 기술 중 하나에 의해 수행되는데요, 예를 보며 이해해보겠습니다. FTL이 논리 페이지 1000, 1001, 1002, 1003을 작성하여 물리 블록 2에 배치했다고 가정해보겠습니다.

그럼 위와 같은 구조를 갖게 됩니다. 이 상태에서 파일 시스템은 log 블록을 쓰게 되는데요, 위의 그림에서 사용 가능한 블록 중 0번 블록에 log 블록을 쓰도록 하겠습니다.

위의 그림과 같이 구조가 변하게 됩니다. 현재 log 블록은 이전과 동일한 내용으로 작성되었기 때문에 FTL은 switch merge라는 작업을 수행합니다. Log 블록은 페이지 0,1,2,3의 저장 위치가 되며 단일 블록 포인터가 가리키게 됩니다. 그리고 이전 블록인 2번 블록은 지워집니다.
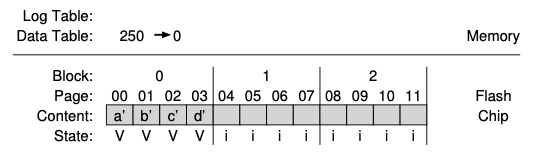
그럼 위와 같이 구조가 바뀌게 됩니다.
방금 알아본 switch merge는 하이브리드 FTL에 적합한 방법입니다. 하지만 만약 방금 본 예의 초기 상태에서 파일 시스템이 논리 블록 1000, 1001만 덮어쓴다면 어떻게 될까요? 이 경우엔 수정하지 않을 블록인 1002, 1003은 블록에서 읽힌 뒤 다음 log에 추가됩니다. 이러한 방법을 partial merge라고 합니다.

즉 위의 그림과 같은 구조로 변하게 됩니다.
마지막으로 FTL에서 단일 블록 포인터로만 참조할 수 있도록 하는 방법에는 full merge가 있습니다. FTL은 cleaning을 수행하기 위해 다른 블록들에서 페이지를 함께 가지고 와야 합니다. 예를 들어 논리 블록 0, 4, 8, 12가 log 블록 A에 기록되어 있을 때 이 Log 블록을 블록 매핑 페이지로 전환하려면 FTL은 논리 블록 0,1,2,3을 포함하는 데이터 블록을 만들어야 하며 FTL은 다른 곳에서 1,2,3을 읽은 뒤 0,1,2,3을 함께 써야 합니다. 그런 뒤 merge는 논리 블록 4에 대하여 동일한 작업을 수행하여 5,6,7을 찾고 물리적 블록으로 다시 연결해야 합니다. 물론 8, 12 블록에도 동일한 작업을 수행하면 됩니다. 이렇게 하면 드디어 log 블록 A를 해제할 수 있게 됩니다. 한눈에 봐도 성능을 나쁘게 할 것 같은 full merge는 될 수 있으면 수행하지 않도록 하는 것이 좋습니다.
Page Mapping Plus Caching
방금 알아본 하이브리드 방식은 조금 복잡하여 사람들은 FTL의 메모리 로드를 줄이는 더 간단한 방법을 제안했습니다. 가장 간단한 방법은 FTL의 활성 부분만 메모리에 캐시 하여 필요한 메모리의 양을 줄이는 방법일 거예요.
이 방법은 어떤 워크로드가 작은 페이지 집합에만 접근하는 경우 해당 페이지의 번역은 메모리의 FTL에 저장되며 메모리 접근 비용을 많이 줄일 수 있습니다. 성능이 좋지 않은 경우도 있을 수 있는데요, 메모리에 캐시 된 부분이 없다면 데이터에 접근하기 전에 매핑 정보를 가지고 오기 위해 읽기 작업을 추가로 수행해줘야 합니다. 또한 캐시 공간에 새로운 매핑 정보를 추가할 공간이 부족하다면 오래된 매핑 정보를 제거해야 하는데, 이로 인한 오버헤드도 발생합니다.
하지만 대부분의 경우 워크로드는 지역성을 표시하고 캐싱 접근 방식은 메모리 오버헤드를 줄이고 성능을 높게 유지합니다!
Wear Leveling
마지막으로 FTL이 플래시 기반 SSD를 위해 구현해줘야 하는 Wear Leveling에 대해 알아보겠습니다. 플래시 칩은 쓰고 지울 때마다 마모가 되는데 만약 같은 공간만 계속 쓰고 지운다면 특정 부분이 마모되어 사용할 수 없게 됩니다. 따라서 FTL은 플래시 칩에 데이터를 골고루 분산시켜 비슷하게 마모되도록 해야 합니다.
기본적인 log-structed 접근 방법은 write 부하를 분산시키는 좋은 초기 작업을 수행하고 garbage collection에도 도움이 됩니다. 하지만 가끔 블록은 오랫동안 유지되는 데이터로 채워질 수 있고 이러한 부분은 다른 부분에 비해 마모가 되지 않을 수 있습니다.
이러한 문제를 해결하기 위해 FTL은 이런 블록에 대해 유효한 데이터를 주기적으로 읽고 다른 곳에 다시 써서 해당 블록을 사용 가능하도록 만들어줍니다. 즉 공평함을 위해 강제로 필요 없는 작업을 수행하는 것인데요, 이렇게 하면 마모되지 않는 곳이 존재하지 않게 할 수는 있지만 성능이 저하됩니다.
SSD Performance And Cost
그럼 도대체 이렇게 복잡하게 만들어야 하는 SSD의 성능은 HDD에 비해 어떤지에 대해 알아보겠습니다.
Performance
하드 디스크 장치와 달리 플래시 기반 SSD에는 기계적 요소가 없어서 seek time, rotate time이 없으며, 랜덤 접근 장치라는 점에서 DRAM과 유사합니다. 성능에서 가장 큰 차이를 보이는 부분은 랜덤 읽기, 쓰기를 할 때 발생합니다. 일반적인 디스크 장치는 초당 랜덤 I/O를 수백 개 정도 처리하지만 SSD는 훨씬 더 많이 수행할 수 있습니다.

위의 표는 SSD 3개와 HDD 1개의 성능을 나타낸 표입니다. HDD와 SSD들의 가장 큰 차이점은 랜덤 I/O의 처리량으로 볼 수 있습니다. 또한 SSD의 랜덤 읽기의 경우 랜덤 쓰기보다 성능이 좋지 않은 것도 볼 수 있습니다. 랜덤 쓰기의 성능이 좋은 이유는 이번 글에서 간단하게 알아본 log structed 설계로 인해 랜덤 쓰기가 연속 쓰기로 변환되어 성능이 향상되기 때문입니다. 연속 I/O의 경우에도 SSD가 HDD보다 성능이 좋은 것을 볼 수 있습니다.
Cost
그럼 이렇게 성능이 좋은 SSD를 쓰면 되지 왜 아직도 HDD를 쓰는 걸까요? 이유는 SSD가 비싸기 때문입니다. SSD와 HDD의 같은 크기에 대한 가격은 몇 배씩 차이가 나기 때문에 구매가 망설여지기도 해요.
그래서 SSD, HDD를 함께 사용해서 자주 사용하는 데이터는 SSD에, 그렇지 않은 데이터는 HDD에 사용하는 형태로 사용하는 사용자가 많고 저도 그렇게 사용하고 있습니다.ㅎㅎ;;
Summary
이번 글에서는 플래시 기반 SSD에 대해 간단하게 알아봤습니다. 플래시 칩의 특징을 숨겨서 일반적인 파일 시스템에서 사용할 수 있도록 해주는 FTL, 플래시 칩의 특징 때문에 비효율적인 작업을 보완하기 위한 Log-structed, 그리고 log-structed를 사용할 때 필요한 mapping table과 이를 최적화하는 방법에 대해 알아봤습니다. 공부를 하면서 가장 어려웠던 단원이었던 것 같고 아직도 확실히 이해를 하진 못한 거 같아요ㅠ 좀 더 공부해야겠습니다. 다음 글에서는 데이터 무결성과 보안에 대해서 알아보도록 하겠습니다!
감사합니다.
'Computer > Operating System' 카테고리의 다른 글
| [OS] Log-structed File System 알아보기 - OS 공부 31 (0) | 2021.02.27 |
|---|---|
| [OS] 파일시스템의 consistency(일관성)를 위한 FSCK, Journaling - OS 공부 30 (1) | 2021.02.24 |
| [OS] Fast File System의 File System 성능향상 아이디어 - OS 공부 29 (0) | 2021.02.17 |
| [OS] 간단한 FileSystem 구현 방법 - OS 공부 28 (2) | 2021.02.08 |
| [OS] File과 Directory - OS 공부 27 (1) | 2021.02.06 |
- Total
- Today
- Yesterday
- dfs
- 코테
- Combine
- 동시성
- Publisher
- 문법
- mac
- 백준
- OSTEP
- pattern
- Xcode
- DP
- 아이폰
- Swift
- design
- document
- BFS
- 자료구조
- System
- 스위프트
- 알고리즘
- 테이블뷰
- operator
- Apple
- operating
- 프로그래밍
- OS
- 앱개발
- 코딩테스트
- IOS
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |