
티스토리 뷰
[OS] Log-structed File System 알아보기 - OS 공부 31
Dev_Pingu 2021. 2. 27. 13:19안녕하세요 Pingu입니다.🐧
지난 글에서는 파일 시스템의 Consistency(일관성)을 위한 FSCK, Journaling과 같은 방법들에 대해 알아봤었습니다. 이번 글에서는 또 하나의 파일 시스템에 대해 알아볼 예정인데요, 바로 Log-structed File System(LFS)입니다. 제가 공부할 때 참고하고 있는 책인 OSTEP에서는 Chapter 43 - Log-Structed File System(LFS) 부분입니다!
Log-structured File Systems
1990년대 초 Ousterhout 교수님과 Mendel Rosenblum이라는 대학원생이 Log-structed File System이라는 새로운 파일 시스템을 개발하게 되는데요, 새로운 파일 시스템을 만든 이유는 무엇일까요?
- 시스템 메모리의 증가 : 메모리가 커질수록 더 많은 데이터가 메모리에 캐시 될 수 있었는데요, 이에 따라 디스크의 읽기 작업이 메모리의 캐시에 의해 서비스되고 이는 결국 디스크의 쓰기 작업의 비중이 높아지는 원인이 되었습니다. 따라서 파일 시스템의 성능이 읽기 작업보다는 쓰기 작업에 의해 결정되게 되었죠!
- 지금까지 알아본대로 디스크는 랜덤 I/O와 연속적인 I/O 와의 성능 차이가 컸습니다. 하드 디스크의 성능이 좋아지면서 대역폭이 증가했지만 Seek time, rotate time 비용은 크게 줄어들지 않았습니다. 따라서 Seek time, rotate time을 줄일 수 있도록 디스크를 연속적으로 사용하고자 했습니다.
- 기존 파일시스템의 몇몇 워크로드에서의 나쁜 성능 : FFS는 한 블록의 파일을 만들기 위해 많은 쓰기 작업을 수행했었는데 기억하시나요? inode도 써야 하고 inode bitmap, data block data bitmap를 업데이트해줘야 했죠. 이러한 작업을 동일한 그룹에서 진행하여 성능을 좋게 만들려고 했으나 그렇게 해도 seek time, rotate time은 발생하게 되고 이는 결국 성능 저하로 이어지게 됩니다.
- RAID 인식 : RAID4, RAID5 모두 단일 블록에 대한 쓰기와 같은 작은 쓰기 작업에 대해 4개의 I/O가 발생하는 문제가 있었습니다. 기존의 파일 시스템은 이렇게 비효율적인 RAID 쓰기 작업을 효율적으로 수행할 방법이 없었습니다.
이와 같은 이유로 파일 시스템을 더 빠르게 만들고 싶었고 이를 위해 Log-structed File System을 만들게 됩니다. LFS는 디스크에 뭔가를 쓸 때 모든 업데이트를 메모리의 세그먼트에 버퍼링 합니다. 세그먼트가 가득 차면 이를 디스크에 순차적으로 한 번에 기록합니다. 이때 무엇을 덮어쓰는 것이 아닌 항상 새로운 위치에 쓰게 되고 세그먼트가 크기 때문에 디스크가 효율적으로 사용되고 파일 시스템의 성능이 좋아지게 됩니다! 그럼 이러한 LFS를 한 번 자세히 알아보도록 하겠습니다.
Writing To Disk Sequentially
방금 LFS는 쓰기 작업을 메모리에 버퍼링 해뒀다가 이를 세그먼트 단위로 디스크에 연속적으로 써준다고 했는데요, 이렇게 처리하는 방법은 무엇일까요? 데이터 블록 D를 파일에 쓰는 예를 살펴보며 이해해보겠습니다.

위와 같이 디스크에 디스크 블록 D가 있는데요, 이렇게 디스크 블록을 쓸 땐 해당 데이터만 쓰는 것이 아니라 inode와 같은 메타데이터도 써줘야했었죠? 따라서 디스크 블록 D를 위한 inode도 써줍니다.

이렇게 블록 D를 가리키는 inode를 만들어줍니다. 이렇게 파일 업데이트에 필요한 정보들을 연속적으로 쓰는 것이 LFS의 핵심이라고 할 수 있습니다. 이로 인해 디스크 블록, inode를 업데이트할 때 seek time, roate time이 필요하지 않게 되는 것이죠!
Writing Sequentially And Effectively
하지만 디스크에 연속적으로 쓴다는 것 만으로는 효율적인 쓰기라고 하기엔 이릅니다.

위와 같이 A 주소에 뭔갈 쓰고 다음 쓰기를 기다렸다가 A+1를 쓴다면 다음 쓰기를 기다리던 도중에 디스크가 회전하기 때문에 rotate time이 발생합니다. 즉 그냥 순차적으로 쓰는 것만으로는 효율적이진 못하단 것이죠. 즉 어느 정도의 쓰기를 모은 뒤 이를 한 번에 디스크에 써줘야 효율적으로 쓸 수 있습니다.
이를 위해 LFS는 buffering1 이라는 기술을 사용합니다. 디스크에 쓰기 전에 LFS는 메모리에서 업데이트를 봅니다. 어느 정도 쓰기 작업이 모이면 이를 한 번에 디스크에 씁니다. 이때 쓰기 작업의 단위를 segment라고 하며 결국 segment 단위로 디스크에 쓰기 작업을 연속적으로 수행하게 됩니다.

위의 그림은 LFS가 segment 단위로 디스크에 쓰기작업을 한 예입니다. 두 개의 업데이트가 있는 것을 볼 수 있는데요, 여러 업데이트라도 segment 단위로 한 번에 디스크에 쓰기 때문에 성능이 좋아지게 됩니다.
How Much To Buffer?
그럼 LFS에서 디스크에 한 번에 쓰는 단위인 segment의 크기는 얼마 정도로 하는 게 좋을까요? 물론 이 크기는 디스크의 성능에 따라 다르겠지만 변수를 사용해서 나타내 보겠습니다. 디스크의 어떤 주소를 찾아가는데 Tp초가 걸린다고 해보겠습니다. 또한 디스크 전송 속도가 R MB/s라고 한다면 이 디스크를 사용할 때 LFS의 버퍼 크기는(segment) 얼마가 좋을까요? Segment의 크기가 크면 클수록 성능이 좋아지긴 할 텐데요, 그럼 D MB 크기를 디스크에 쓰는 예를 실제로 계산해보겠습니다. 즉 여기서 D가 segment의 크기라고 할 수 있습니다.

이렇게 계산한 값으로 쓰기 작업의 크기를 쓰기 시간으로 나눈 유효 쓰기 속도(Reffective)를 구하면

위와 같이 계산됩니다. 우리는 유효 쓰기 속도인 Reffective가 큰 값을 얻고 싶고 이 값이 커진다면 대역폭의 최대 효율을 낼 수 있게 됩니다. 대역폭 사용량을 F라고 할 때 F * 디스크 성능이 Reffective가 되는데요, 지금까지 얻어낸 식으로 새로운 식을 얻을 수 있습니다.

위와 같이 계산을 해서 Tp = 10ms, 대역폭이 100MB/s인 디스크에 90%의 대역폭을 사용할 때에 D를 구해보면 아래와 같습니다.

즉 LFS를 사용해서 Tp = 10ms, 대역폭이 100MB/s인 디스크에 90%의 대역폭을 사용하고 싶다면 9MB크기의 segment를 사용하면 됩니다.
Problem: Finding Inodes
그럼 이번엔 LFS에서 inode를 찾는 방법을 알아보겠습니다. LFS에서 inode를 찾는 방법을 알아보기 전에 지금까지 배운 파일 시스템들이 inode를 어떻게 찾았던가에 대해 생각해볼까요? FFS, UNIX File System의 경우 디스크의 특정 위치에 inode를 위치시키기 때문에 찾기가 쉬웠습니다. 하지만 LFS는 아까 봤던 대로 segment의 어딘가에 inode들이 흩어져 있습니다. 따라서 기존처럼 inode를 찾을 수가 없게 되었죠! 그럼 LFS에서는 inode를 어떻게 찾아야 할까요?
Solution Through Indirection: The Inode Map
LFS에서는 흩어진 inode들을 찾기 위해 inode map이라는 자료구조를 사용하여 inode들의 거리를 계산합니다. inode map은 inode 번호를 입력으로 받아서 최신 inode 디스크 주소를 생성하는데요, LFS는 항상 새로운 위치에 데이터들을 쓰기 때문에 inode가 업데이트 될 때마다 inode map도 inode의 새로운 위치를 업데이트해줘야 합니다.
이러한 inode map은 디스크에 영구적으로 존재해야 하는데요, inode map은 디스크의 어디에 위치해야 할까요? 기존처럼 디스크의 특정 부분에 inode map을 위치시켜도 되지만 이렇게 하면 inode를 업데이트할 때마다 inode map을 찾아가는 비용 때문에 성능이 저하됩니다. 따라서 LFS는 inode가 새로 써지는 위치 바로 옆에 inode map을 함께 습니다. 즉 파일에 블록을 추가할 때 LFS는 데이터 블록, inode, inode map을 한 번에 쓰게 되는 것이죠.

위의 그림은 LFS가 쓰기 작업을 하고 난 뒤의 디스크 이미지입니다. 데이터 블록, inode, inode map이 함께 써진 것을 볼 수 있습니다.
Completing The Solution: The Checkpoint Region
근데 흩어진 inode를 찾겠다고 inode map을 만들었는데 결국 inode map도 흩어지게 되었습니다. 그럼 inode map은 어떻게 찾아야 할까요?? 결국 디스크의 특정 부분에 Checkpoint Region(CR)이라는 inode map을 찾기 위한 데이터를 갖게 되는데요, LFS는 CR을 읽어서 inode map의 위치를 알아내고 inode의 위치도 알아내게 됩니다.
이러한 CR은 30초와 같이 긴 주기를 가지고 업데이트되기 때문에 성능에 큰 영향을 주지 않는다고 합니다. 결국 LFS 파일 시스템을 사용하는 디스크는 아래와 같은 구조를 가지게 됩니다.

Reading A File From Disk: A Recap
그럼 지금까지 알아본 정보에 따라 LFS에서 파일을 읽는 과정을 한 번 보겠습니다. LFS를 사용하는 디스크에서 어떤 파일을 읽고 싶다면 가장 먼저 Checkpoint Region을 찾아야 합니다. 여기엔 LFS의 모든 inode map에 대한 포인터가 있기 때문에 이를 메모리에 캐시 합니다. 첫 접근 이후에는 메모리에서 CR을 사용하여 성능을 좋게 만들 수 있는 것이죠. CR에서 inode map의 주소로 가게 되고 inode map에서 inode의 주소를 찾게 됩니다. inode에서는 데이터 블록의 주소로 이동하게 되며 이렇게 데이터 블록을 찾을 수 있게 됩니다.
LFS는 기존의 FFS, UFS에서 파일을 찾는 과정에서 inode map을 메모리에 캐싱하고 이를 사용하여 inode map에서 inode를 찾는 작업이 추가된다는 것을 알 수 있습니다.
What About Directories?
이번에는 LFS에서 디렉터리 데이터를 저장하는 방법에 대해 알아보겠습니다. LFS에서 디렉터리의 구조는 UNIX File System과 동일합니다. 즉 디렉터리는 자신에게 포함된 파일의 inode들이 저장되어있는데요, LFS에서는 파일을 수정할 때 데이터 블록, inode, inode map을 함께 만들어야 하기 때문에 이를 디렉터리와 함께 만드는 과정을 살펴보겠습니다.
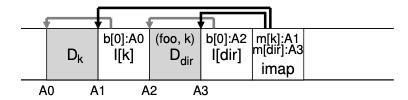
위의 그림은 디렉터리에 foo라는 파일을 만들었을 때 디스크 구조입니다. inode map은 디렉토리(dir)와 foo라는 파일의 inode 주소를 가지고 있습니다. 그리고 디렉토리 inode에는 자신에게 속한 파일인 foo의 inode를 가지고 있습니다. 그리고 그 inode로 foo의 데이터 블록인 A0에 접근할 수 있게 됩니다.
그런데 LFS는 데이터가 업데이트될 때마다 새로운 위치에 쓴다고 했잖아요? 그렇다면 디렉터리의 데이터도 매번 변경해야할까요? 만약 그렇게 된다면 디렉토리 트리구조를 매번 바꿔줘야하는 문제가 발생합니다. 하나의 파일을 수정했더니 파일 시스템 전체의 구조를 바꿔야할수도 있는 것이죠.
LFS는 이러한 문제를 inode map으로 해결했는데요, inode의 위치는 변경될 수 있지만 이는 디렉토리 자체에는 반영되지 않습니다. 디렉터리는 이름-inode number의 쌍을 그대로 갖고 있고 inode map만 업데이트되는 것이죠. 이러한 indirection을 통해 LFS는 업데이트 문제를 해결했습니다.
A New Problem: Garbage Collection
지금 까지 알아본 LFS에서는 매번 데이터를 새로운 위치에 쓴다고 했는데요, 그럼 기존에 존재하던 데이터는 어떻게 처리해야 할까요? 데이터가 업데이트가 된다면 기존 데이터는 필요 없게 되고 이를 처리할 방법이 필요합니다.

예를 들어 위와 같이 A0에서 시작하는 파일이 있었는데 업데이트가 되어 A4에 다시 쓰였다고 해보겠습니다. 위의 그림에서는 inode map과 디렉터리 정보와 같은 블록이 생략되었는데, 원래는 걔네도 있어야 합니다. 그렇다면 이번엔 파일에 블록을 추가하는 작업을 살펴보겠습니다.

위의 그림처럼 D0블록만 있던 파일에 D1블록이 추가되었습니다. 이 경우엔 inode에 새로운 블록의 주소만 추가하고 기존 블록의 주소는 유지하면 됩니다. 이번에는 inode만 업데이트한 것입니다. 그럼 과거의 inode 데이터로는 뭘 할 수 있을까요? 파일을 복원하거나 버전을 추적하는 데 사용할 수 있습니다. 하지만 디스크는 한정된 자원이고 데이터를 쓸 때마다 기존 데이터를 계속 유지한다면 이는 디스크 낭비로 이어질 수 있습니다. 따라서 LFS는 파일의 최신 버전만 유지하게 되는데요, 이에 따라 예전 데이터들을 제거해줘야 합니다. 이렇게 이전 데이터를 정리하는 작업을 garbage collection이라고 합니다.
Garbage Collection을 하지 않으면 LFS에서는 디스크 낭비뿐만 아니라 segment를 위한 연속 공간을 찾는데도 문제가 발생하기 때문에 성능에 영향을 줍니다. 그럼 LFS에서 Garbage Collection이 처리되는 과정을 살펴볼까요? LFS Cleaner가 이러한 일을 담당하며 클리너는 주기적으로 segment를 읽고 어떤 블록이 있는지 확인 한 뒤 유효한 블록들로 새로운 segment를 만들어 이전의 segment를 제거합니다. 즉 어떤 segment에서 필요 없는 데이터를 없앤 새로운 segment를 만들어 이를 사용하게 됩니다.
그렇다면 이러한 클리너는 얼마나 자주 동작해야 하며 유효한 블록들은 어떻게 알아낼 수 있을까요?
Determining Block Liveness
Garbage Collection를 위한 클리너가 동작하기 위해선 유효한 블록인지 판단할 수 있어야 하는데 이를 위해 LFS는 segment 헤더 블록에 존재하는 블록의 정보에 inode 번호와 offset을 함께 넣어두게 됩니다. 이를 통해 유효한 블록인지 판단하게 됩니다. 이 과정을 간단하게 살펴보면 아래와 같습니다.

위의 그림은 파일 k가 있고 이 파일의 블록 중 유효한 블록을 찾는 그림입니다. 헤더 블록에 A0: (k,0)이라는 정보가 보이시나요? 이 정보가 inode, offset 정보인데요, 이를 통해 k 파일의 유효한 블록을 찾을 수 있습니다.
A Policy Question: Which Blocks To Clean, And When?
그럼 이번에는 클리너가 어떤 주기로 어떤 블록에 대해 garbage collection을 수행해야 하는지 살펴보겠습니다. 일단 블록을 정리할 시간은 그냥 주기적으로 하거나 디스크가 가득 찼을 때와 같은 경우에 하면 됩니다.
더 어려운 문제는 어떤 블록을 정리할 것이냐에 대한 문제인데요, 이를 위해 segment를 hot, cold segment로 나누게 됩니다. Hot Segment는 데이터를 자주 덮어쓰는 segment입니다. 따라서 많은 블록을 모아서 한 번에 처리하는 게 효율적입니다.
Cold Segment는 블록들 중 필요 없는 게 있을 수 있지만 segment 자체에 영향은 주지 않는 segment입니다. 따라서 LFS 논문에서는 Cold Segment를 먼저 처리하는 게 낫다고 하는데요, 지금까지 OS를 공부하며 느낀 건 완벽한 정책은 없었고 이러한 정책도 역시나 완벽하진 않다고 합니다.
Crash Recovery And The Log
그럼 마지막으로 파일 시스템의 중요한 부분인 만약 데이터를 쓰다가 문제가 발생했을 때 어떻게 복구할 것이냐에 대한 부분을 살펴보겠습니다. 정상적으로 LFS가 작동한다면 segment를 디스크에 쓰고 이를 log로 구성할 거예요. 그러면 Checkpoint Region이 head, tail segment를 가리키고 각 segment는 다음 segment를 가리킬 거예요. 그리고 클리너가 주기적으로 garbage collection을 수행하겠죠? 이러한 과정 중 segment에 쓸 때, Checkpoint region에 쓸 때에 충돌이 발생할 수 있습니다. LFS는 이러한 충돌을 어떻게 해결할까요?
일단 Checkpoint Region을 쓸 때 발생하는 충돌을 해결하는 방법을 살펴보겠습니다. Checkpoint Region 업데이트를 원자적으로 수행하기 위해 LFS는 실제로는 디스크의 양 끝에 Checkpoint Region를 하나씩 유지하고 교대로 기록한다고 합니다. 즉 Checkpoint Region이 2개인 것이죠! LFS는 Checkpoint Region를 업데이트할 때 헤더, Checkpoint Region 본문, 마지막 블록을 기록하게 되는데요, 여기서 헤더와 마지막 블록에 시간 정보가 들어가게 됩니다. Checkpoint Region 업데이트 중에 충돌이 발생할 경우 LFS는 헤더와 마지막 블록의 시간을 확인해서 일치하지 않는다면 다시 쓰게 됩니다. 이렇게 LFS는 Checkpoint Region의 일관성을 유지할 수 있게 됩니다.
그럼 이번엔 Segment에 쓸 때 발생하는 충돌을 살펴보겠습니다. LFS는 Checkpoint Region을 30초에 한 번 정도의 주기로 업데이트하기 때문에 이미 파일 시스템에 존재하는 정보는 오래된 정보일 수 있습니다. 예를 들어 segment만 쓰고 이제 Checkpoint Region를 업데이트하려고 하는데! 컴퓨터가 꺼졌습니다. 이러한 상황에서 컴퓨터를 재부팅해서 업데이트되지 않은 Checkpoint Region 정보로 복구하게 된다면 마지막 segment 업데이트가 손실되게 됩니다. 이를 해결하기 위해 마지막 Checkpoint Region에서 시작하여 log의 끝을 찾고 이를 사용하여 다음 segment를 읽고 업데이트가 존재하는지 확인하여 만약 필요하다면 이를 업데이트해주면 됩니다.
Summary
이번 글에서 알아본 LFS는 디스크를 사용하는 새로운 방법을 도입합니다. 파일을 덮어쓰는 대신 항상 새로운 공간에 데이터를 쓰게 되고 이전 데이터는 garbage collection으로 처리하게 됩니다. 또한 이러한 과정에서 디스크를 항상 연속적으로 사용하기 때문에 성능이 좋았습니다.
이러한 LFS는 RAID4, 5와 같은 parity 기반 RAID에서 발생하는 작은 쓰기 문제를 방지할 수 있으며 최근에 많이 사용하는 Flash based SSD에서 좋은 성능을 얻으려면 대용량 I/O가 필요하다는 연구가 있고 이러한 것에 LFS가 활용될 수 있다고 합니다.
하나의 단점은 쓸데없는 파일들이 많이 만들어진다는 것인데 이를 garbage collection을 통해 해결할 수 있었습니다. 다음 글에서는 방금 LFS를 사용하면 좋다는 Flash based SSD에 대해 살펴보도록 하겠습니다.
'Computer > Operating System' 카테고리의 다른 글
| [OS] Flash 기반 SSD의 구조 - OS 공부 32 (1) | 2021.03.05 |
|---|---|
| [OS] 파일시스템의 consistency(일관성)를 위한 FSCK, Journaling - OS 공부 30 (1) | 2021.02.24 |
| [OS] Fast File System의 File System 성능향상 아이디어 - OS 공부 29 (0) | 2021.02.17 |
| [OS] 간단한 FileSystem 구현 방법 - OS 공부 28 (2) | 2021.02.08 |
| [OS] File과 Directory - OS 공부 27 (1) | 2021.02.06 |
- Total
- Today
- Yesterday
- 동시성
- 코딩테스트
- System
- OSTEP
- dfs
- design
- document
- Swift
- 문법
- 스위프트
- operating
- OS
- DP
- Publisher
- 앱개발
- Xcode
- Combine
- 코테
- 아이폰
- 알고리즘
- IOS
- 백준
- operator
- 자료구조
- BFS
- pattern
- 프로그래밍
- mac
- Apple
- 테이블뷰
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |