
티스토리 뷰
안녕하세요 Pingu입니다.🐧
지난 글에서는 파일 시스템에서 가장 중요한 두 요소인 File, Directory에 대해 알아봤었습니다. 이번 글에서는 파일 시스템 자체를 구현하는 방법에 대해 알아볼 예정인데요, 이전 글까지도 계속 등장한 inode부터 시작해서 다양한 파일 시스템의 개념에 대해 알아보도록 하겠습니다. 제가 공부할 때 참고하고 있는 책인 OSTEP에서는 Chapter 40 - File System Implemention 부분입니다!
File System Implementation
이번 글에서는 VSFS(the Very Simple File System)으로 알려진 간단한 파일 시스템을 구현하는 방법을 알아볼 예정입니다. VSFS는 UNIX의 여러 가지 파일 시스템을 단순화한 것으로 이를 공부하면 파일 시스템의 기본 동작들을 알 수 있습니다.
이번 글에서 알아볼 파일 시스템은 CPU, 메모리 가상화와 달리 하드웨어의 지원은 받지 않는 오로지 소프트웨어로만 동작하도록 만들 예정이며 VSFS라는 이름에서 알 수 있듯 아주 간단하게 만든 것이므로 실제 파일 시스템과는 다를 수 있습니다.
The Way To Think
그럼 글을 시작하기 전에 파일 시스템을 어떻게 만들 수 있을지, 필요한 자료구조는 무엇이고 해당 자료 구조에 접근하는 방법은 어떻게 될지에 대해 생각해본 뒤 시작해보겠습니다. 파일 시스템은 두 가지 측면에서 생각하는 것이 좋은데요, 이는 자료 구조, 접근 방법입니다.
자료 구조의 경우엔 파일 시스템에서 데이터와 메타 데이터를 구성하기 위해서 어떤 디스크 구조를 사용할 것인가에 대한 것인데, vsfs의 경우엔 블록 배열을 사용하지만 어떤 파일 시스템은 복잡한 트리 기반 구조를 사용하기도 합니다.
두 번째는 접근 방법입니다. 즉 방금 고려한 자료구조에 어떻게 접근할 것인지에 대한 것이죠. open(), read(), write() 등과 같은 프로세스의 호출을 어떻게 처리할지, 그리고 얼마나 효율적으로 수행되는지에 대한 것입니다.
그럼 이러한 것들을 고려해보며 글을 시작해보도록 하겠습니다.
Overall Organization
이전 글에서도 언급된 적이 있는데 디스크는 블록으로 나눌 수 있었습니다. 파일 시스템은 블록 크기를 정해서 사용하는데 보통 4KB를 사용한다고 하니 저도 4KB 블록을 사용하도록 하겠습니다. 따라서 디스크 파티션을 하게 되면 해당 디스크는 4KB의 블록들로 구성된다는 말이 됩니다. 그럼 64개의 블록이 있는 디스크가 있다고 생각해고 해당 블록에는 어떤 정보가 저장될 것인지에 대해 알아보겠습니다.

일단 하나의 블록이 4KB의 크기를 가진다고 했으니 위와 같이 64개의 블록을 가진다면 64 * 4KB = 256KB 크기를 갖는 디스크가 됩니다. 해당 블록들은 0~63까지의 번호를 갖게 되며 이러한 블록에 데이터를 저장하게 됩니다.

그럼 블록들에는 어떤 데이터를 저장하면 될까요? 먼저 디스크에서 대부분의 공간을 차지하는 사용자 데이터를 저장해야 될 것 같아요. 사용자 데이터는 그냥 사용자가 사용하는 프로그램, 파일 등을 말합니다. 사용자 데이터가 차지하는 디스크 영역을 Data Region이라고 부르며 지금 예로 들고 있던 블록 64개짜리 디스크에서 위의 그림과 같이 8~63번 블록들을 사용자 데이터로 사용하겠다고 정하겠습니다.

그럼 이제 이러한 사용자 데이터에 대한 정보가 필요하고 이러한 데이터를 메타 데이터라고 부른다고 했었습니다. 파일 크기, 접근 권한, 접근, 수정시간 등의 정보를 저장하는 데이터는 일반적으로 inode라는 구조로 되어있습니다. 또한 디스크에는 이러한 inode에 대한 정보를 저장할 공간도 확보해야 하죠. 이러한 공간을 inode table이라고 하며 지금 예에서는 위의 그림과 같이 3~7번 블록을 inode table로 사용한다고 정해보겠습니다. inode 하나의 크기는 128B, 256B와 같이 그렇게 크지 않은데, 지금 예에서는 inode 하나의 크기를 256B라고 한다면 디스크 블록 하나당 inode가 16개를 수용할 수 있게 됩니다.

그럼 또 어떤 정보가 필요할까요? 사용자 데이터가 있고 그러한 데이터를 추적할 수 있는 inode들도 저장하는 공간을 확보했으니 이젠 그러한 공간에 inode, data를 저장할 수 있는지에 대한 여부를 알 수 있는 정보를 저장해야 될 것 같아요. 즉 특정 공간이 사용 가능한지에 대한 여부를 저장할 공간을 확보하겠다는 말인데, 이러한 정보를 bitmab이라고 하며 지금 디스크에는 inode table, data region이라는 두 영역이 있으니 각각의 영역마다 하나의 블록을 사용하게 하면 될 것 같아요. 위의 그림과 같이 2개의 블록에 이러한 데이터를 저장하겠다고 정해보겠습니다.

그럼 이제 딱 한 개의 블록만 남은 상태인데요, 여기엔 어떤 정보를 저장하려고 아직까지 남겨뒀을까요? 여기엔 Super block이라고 불리는 정보를 저장하기 위한 공간으로 남겨뒀습니다. 슈퍼 블록은 파일 시스템에 존재하는 inode 블록 수, 데이터 블록 수, inode table이 시작되는 위치, data region이 시작되는 위치와 같은 파일 시스템에 대한 정보를 저장합니다. 파일 시스템의 종류를 구분하기 위한 매직 넘버도 여기에 들어있습니다. 디스크는 위와 같은 구조로 사용되는 것을 알 수 있습니다.
File Organization: The Inode
이전 글들에서도 계속 언급되던 inode는 파일 시스템에서 가장 중요한 디스크 구조 중 하나입니다. inode는 index node의 줄임말로 예전에 파일의 하위 수준 이름이라고 했었습니다. 이러한 inode 번호가 주어지면 파일 시스템에서는 inode가 있는 디스크의 위치를 계산하여 inode 테이블을 가지고 오고 여기에 맞는 데이터 블록에 접근할 수 있어야 합니다. 예를 보며 이해해볼까요? 아까의 예를 그대로 가지고 와서 하나의 디스크 블록은 4KB이고 하나의 inode는 256바이트라고 가정해보겠습니다. 0번 블록에는 슈퍼블록이, 1,2번 블록에는 bitmap 블록이 있었고 3~7번 블록에 inode정보가 저장된다고 정했었죠? 이를 표현해보면 아래와 같아집니다.

만약 inode 32번을 읽고 싶다면 파일 시스템은 무엇을 하면 될까요? 일단 inode table이 시작되는 위치를 슈퍼블록에서 알아냅니다. 위의 경우엔 12KB가 되겠죠? 그런 뒤 inode 32번이므로 하나의 inode 크기(256B) * 32를 해주시면 됩니다. 이는 결과적으로 8KB가 되며 이 두 개의 값을 더해준 20KB가 inode 32의 위치입니다. 그곳에 가면 실제 data의 위치가 나오게 되고 해당 위치로 가서 데이터를 읽게 됩니다.

그럼 inode 블록에는 어떤 정보가 저장되어 있을까요? 실제 ext2의 inode 블록에 저장된 값은 위와 같습니다. 파일의 크기, 파일의 소유자, 최종 접근 시간, 만들어진 시간 등의 파일에 대한 정보가 저장되어 있고 이를 MetaData(메타 데이터)라고 합니다. inode 블록에는 실제 데이터의 위치에 대한 정보도 존재한다고 했었는데요 가장 간단한 방법은 데이터 블록의 위치를 직접 포인터로 갖는 방법입니다. 이러한 포인터를 direct block Pointer라고 하며 이는 빠르지만 비교적 큰 파일에 대한 것을 처리할 수 없습니다. 예를 들어 위의 Ext2의 inode에 block이라는 필드가 이러한 포인터를 저장하는 필드인데, 15개가 존재하는 것을 볼 수 있습니다. 하나의 디스크 블록이 4KB인 것을 감안한다면 겨우 60KB의 파일만 처리할 수 있는 파일 시스템이 되는 것이죠. 하지만 실제로는 그것보다 훨씬 큰 파일들을 사용하기 때문에 다른 방법이 필요하게 됩니다.
The Multi Level Index
Direct block Pointer만으로는 60KB 보다 큰 파일을 처리할 수 없으므로 다른 방법을 알아봐야 합니다. 그러한 방법 중 하나는 indirect pointer를 사용하는 방법입니다. 바로 데이터 블록을 가리키는 것이 아닌 데이터 블록을 가리키는 포인터가 저장된 블록을 가리키는 것이죠. 이렇게 하면 direct block pointer만 사용할 때와 다르게 더 큰 크기의 파일도 처리할 수 있습니다. 이렇게 글로만 보면 이해가 어려우니 그림을 보며 살펴보도록 하겠습니다.
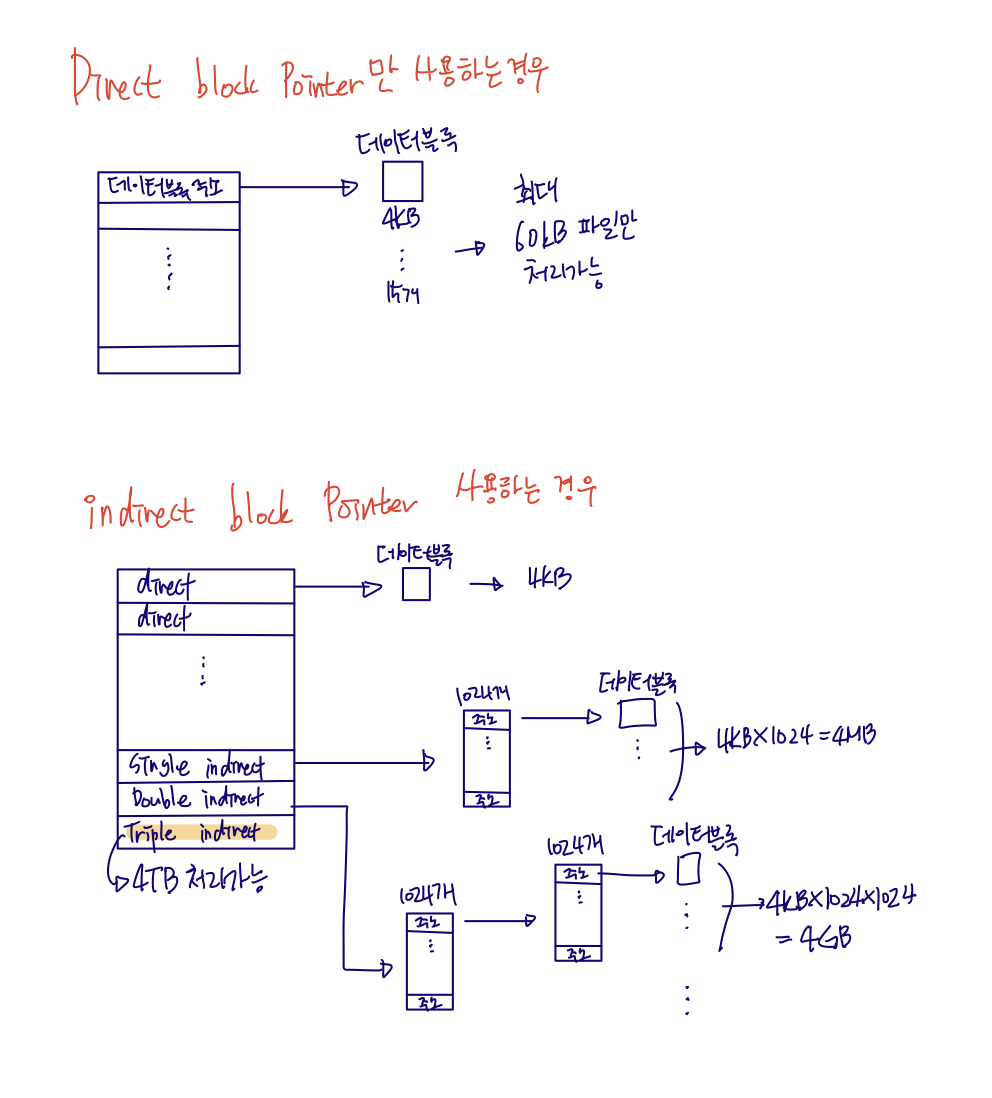
Direct block Pointer만 사용하는 경우는 아까 알아본 대로 60KB까지밖에 지원하지 못합니다. 하지만 inode에 존재하는 15개의 주소 블록에서 3개만 indirect pointer로 사용하면 파일의 크기를 훨씬 크게 지원할 수 있습니다. 예를 들어 한 번 주소 블록을 거쳐 실제 데이터 블록으로 접근하는 single indirect 블록의 경우 inode 블록에서 4KB 크기의 주소 블록에 도착하게 됩니다. 주소 공간 하나를 4바이트로 표현할 수 있다고 할 때 4KB의 블록에는 총 1024개의 디스크 주소를 가질 수 있게 됩니다. 1024개의 디스크 주소가 각각 4KB의 디스크 블록을 가리키게 된다면 결과적으로 4KB*1024 = 4MB라는 크기의 파일을 나타낼 수 있게 됩니다. 동일한 원리로 double indirect 블록은 처음 도착하는 1024개의 주소를 갖는 블록에서 한 번 더 1024개의 디스크 블록 주소를 갖는 블록으로 이동합니다. 즉 이 경우엔 4KB * 1024 * 1024 = 4GB의 크기를 갖는 파일을 나타낼 수 있게 되는 것이죠. 마지막으로 Triple indirect는 4TB 크기의 파일을 나타낼 수 있습니다. 결과적으로 하나의 inode가 나타낼 수 있는 최대 파일의 크기는 48KB + 4MB + 4GB + 4TB가 됩니다.
물론 이렇게 여러 단계에 거쳐 디스크 블록에 접근하는 경우 시간은 더 오래 걸릴 수 있지만 더 큰 파일을 처리할 수 있다는 점이 너무나 큰 장점이라고 볼 수 있습니다. Direct pointer는 작은 파일만 처리 가능하지만 빠르다는 장점이 존재합니다. 또한 대부분의 파일이 그렇게 크지 않다는 연구결과가 있기 때문에 파일 시스템은 두 개의 pointer를 모두 사용하여 속도와 크기를 모두 만족시키는 위와 같은 형태를 사용하게 됩니다.
Directory Organization
VCFS의 디렉터리는 단순한 구성을 갖습니다. 디렉터리는 이전 글에서 알아봤듯 파일 이름과 inode 번호의 쌍을 가지고 있습니다. 즉 이를 표현하면 아래와 같습니다.

위의 표는 디렉터리의 정보를 나타낸 표입니다. foo, bar, foobar_is_a_pretty_longname이라는 3개의 파일이 존재하는 것을 볼 수 있습니다. 파일에는 inode 번호와 record 길이(이름에 사용되는 총길이), 이름의 길이(실제 이름의 길이)가 저장되어있습니다. 여기서 record 길이가 왜 필요한지가 궁금한데요, 저번 글에서 알아본 unlink()를 호출하여 파일을 삭제하면 디렉터리 중간에 빈 공간이 남을 수 있기 때문에 record 길이를 사용하여 이를 처리하는 데 사용합니다.
디렉터리는 파일 시스템에서 볼 땐 특수한 파일로 디렉터리에 대한 inode도 inode table에 존재합니다. 디렉터리에는 inode가 가리키는 데이터 블록이 존재하며 이러한 데이터 블록은 일반적인 파일의 데이터 블록과 동일한 공간에 존재하기 때문에 디스크 구조에 변화를 주지 않습니다.
Free Space Management
파일 시스템은 어떤 inode와 데이터 블록이 사용 가능한지에 대해 알아야 하고 이러한 것을 bitmap이라는 것으로 처리한다고 아까 언급했었습니다. 또한 bitmap에는 두 가지 타입이 있었고 하나는 inode에 관한 것, 하나는 데이터 블록에 관한 것이었습니다.
파일을 하나 만들게 되면 해당 파일에 inode 번호를 할당해줘야 합니다. 이때 파일 시스템은 bitmap을 통해 사용 가능한 inode 번호를 찾고 이를 할당해줍니다. 그런 뒤 bitmap에 해당 inode 번호가 사용되었다고 표시해줍니다. 파일을 만들어서 데이터 블록을 할 때도 동일한 방법으로 할당해줄 수 있습니다. 데이터 블록을 할당해줄 때엔 pre-allocation(선할 당)이라는 방법을 사용하기도 합니다. Ext2, Ext3 파일 시스템의 경우 새로운 파일이 생성되고 데이터 블록을 할당할 때 연속적으로 사용 가능한 블록 범위를 찾습니다. 그런 뒤 이 파일을 여기에 할당하여 파일이 연속적인 디스크 블록에 저장되도록 보장해줍니다. 이 결과로 seek time이 줄어 성능이 좋아질 수 있습니다.
Access Paths: Reading and Writing
이제 파일과 디렉터리가 어떻게 디스크에 저장되는지에 대해 알았으니 파일을 읽고 쓰는 흐름을 알아보도록 하겠습니다. 이러한 흐름을 이해하는 것이 파일 시스템을 이해하는 데 있어 중요하니 잘 알아보도록 하겠습니다. 지금부터 살펴볼 예에서는 파일 시스템이 마운트 되어 슈퍼 블록이 이미 메모리에 있다고 가정하며 다른 데이터들은 디스크에 남아있다고 가정하겠습니다.
Reading A File From Disk
그럼 /foo/bar라는 파일을 읽은 뒤 닫는 작업을 처리할 때 파일 시스템에서 발생하는 일들에 대해 알아보도록 하겠습니다. bar라는 파일은 12KB의 크기를 가지며 하나의 디스크 블록이 4KB이므로 3개의 디스크 블록으로 구성된 파일이라고 할 수 있습니다.
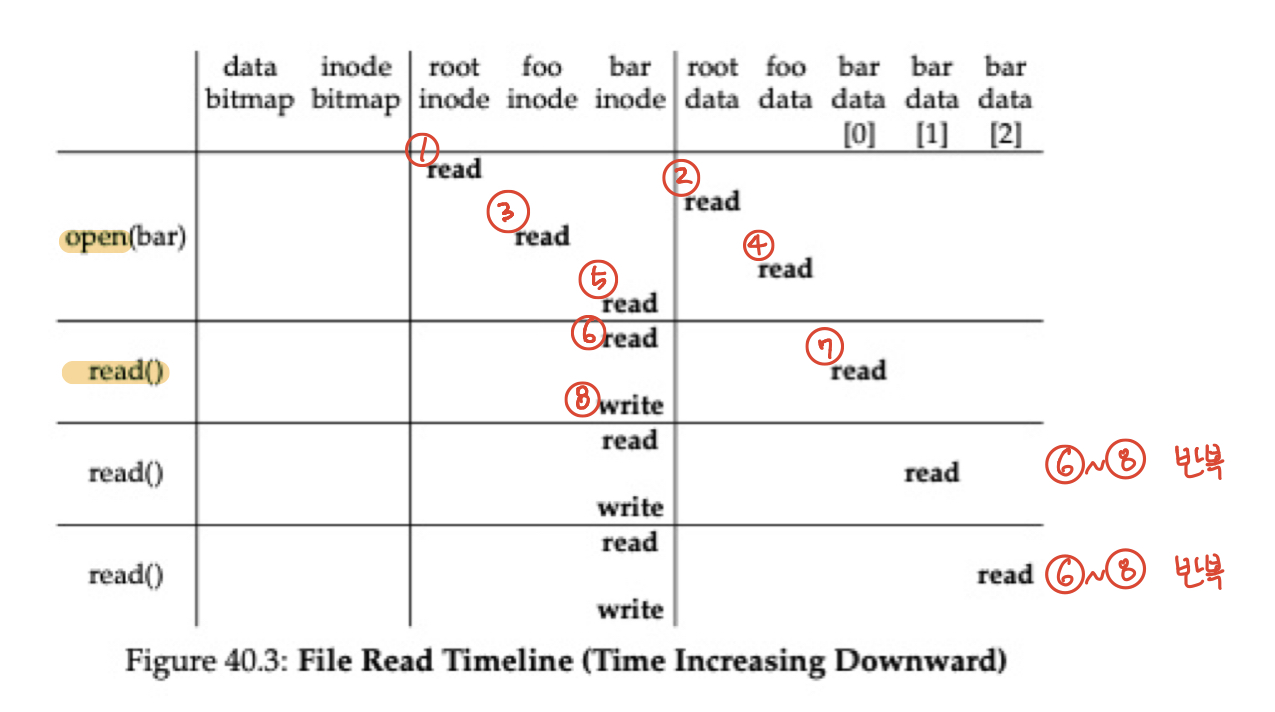
/foo/bar 파일을 읽는 과정은 위와 같습니다. 8번 과정을 보면 읽기 작업만 했는데도 write 작업이 수행된 것을 볼 수 있는데요, 왜 그런지 1번부터 차례대로 살펴보도록 하겠습니다.
1. /foo/bar에 대한 읽기 요청이 발생하면 가장 먼저 root 디렉터리의 inode로 가서 파일에 대한 경로를 알아냅니다. 그런데 root 디렉터리의 inode는 어떻게 알 수 있을까요? root 디렉터리의 inode 위치는 파일 시스템이 마운트 될 때 알려지는데요, 보통 inode 2번을 갖게 됩니다. 어쨌든 root 디렉터리의 inode를 읽어서 root 디렉터리의 데이터 위치로 갈 수 있게 됩니다.
2. root 디렉토리의 data 부분에서 foo라는 이름, inode 쌍을 찾고 해당 inode를 가지고 foo 디렉터리의 inode로 이동합니다.
3. foo 디렉토리의 inode 부분을 읽어서 foo 디렉터리의 data 부분으로 찾아갑니다.
4. foo 디렉토리의 data 부분을 읽어서 bar라는 파일과 inode 번호 쌍을 알아냅니다. 그런 뒤 bar inode로 이동합니다.
5. bar inode로 이동하고 이를 읽으면 bar를 open 할 수 있습니다.
6. 이젠 bar라는 파일을 open 했으니 읽기 작업을 해주면 됩니다. 읽기 위해서는 bar라는 파일의 데이터 블록으로 이동하면 되기 때문에 bar inode를 읽고 데이터 블록의 위치를 알아냅니다.
7. 알아낸 데이터 블록의 위치로 가서 해당 데이터를 읽습니다.
8. 데이터를 읽었다는 것은 접근을 했다는 말이 되기 때문에 최종 접근시간을 inode에 다시 기록합니다.
bar라는 파일은 12KB였고 하나의 데이터 블록의 크기가 4KB였기 때문에 6~8 과정을 3번 해주면 파일을 모두 읽을 수 있게 됩니다. 그렇게 다 읽고 나면 close()를 호출하여 파일을 닫게 됩니다. 이렇게 파일 하나를 읽기 위해서는 생각보다 많은 I/O 작업을 처리해줘야 합니다. 그럼 읽기 작업의 흐름은 알아봤으니 이젠 쓰기 작업의 흐름도 알아보도록 하겠습니다!
Writing A File To Disk
그럼 이젠 쓰기 작업의 흐름을 알아보겠습니다. 읽기 작업과 마찬가지로 파일을 열고 write()를 호출하여 쓰기 작업을 수행하면 되고 끝난 후엔 파일을 close 해주면 됩니다. 읽기와는 다르게 쓰기 작업은 새로운 디스크 블록을 할당할 수도 있습니다. 새 파일을 만들기 위해서는 디스크에 데이터를 기록하는 것뿐만 아니라 할당할 블록을 찾고, bitmap, inode도 업데이트해줘야 합니다. 그럼 어떤 흐름으로 진행되는지 살펴보도록 하겠습니다. 이번 예는 아까 읽은 12KB 크기의 /foo/bar 파일을 만드는 작업입니다.

1. 일단 아까 읽기 작업과 마찬가지로 root inode를 찾아갑니다. 거기서 root 데이터 블록의 위치를 알아내서 이동합니다.
2. root 데이터 블록에서 foo라는 디렉터리와 inode 쌍을 찾습니다. 그런 뒤 foo inode로 이동합니다.
3. foo inode를 읽어서 foo의 데이터 블록 위치로 이동합니다.
4. foo 디렉터리 안에 bar라는 파일을 만들 것인데 현재 권한으로 쓰기 작업을 할 수 있는지에 대한 여부를 알아냅니다. 또한 bar라는 파일이 이미 있는지도 확인해야 합니다. 만약 쓰기 권한이 있고 bar라는 파일이 없다면 아직 새로운 파일을 위한 inode 번호가 없으므로 현재 사용 가능한 inode 번호를 알기 위해 inode bitmap으로 이동합니다.
5. inode bitmap을 읽고 사용 가능한 inode 번호를 찾습니다.
6. 사용가능한 inode 번호를 찾았으면 해당 inode 번호가 사용 중이라고 표시해줍니다.
7. 다시 foo의 데이터 블록으로 돌아와서 bar라는 파일과 이에 할당된 inode 번호를 추가합니다.
8. OSTEP에서는 사용 가능한 inode 블록은 default값으로 설정이 되어있기 때문에 read를 한 뒤 새로운 정보를 write 한다고 되어있습니다. 그래서 여기서 read 작업이 발생합니다.
9. bar에 대한 정보를 bar inode에 write 합니다.
10. bar라는 파일이 생성되며 foo가 수정되었기 때문에 이러한 정보도 업데이트해줍니다. 이렇게 되면 bar를 위한 inode가 생성된 상태입니다.
11. bar inode를 읽고 새로운 데이터 위한 디스크 블록을 할당하기 위해 사용 가능한 디스크 블록을 기록하는 data bitmap으로 이동합니다.
12. 사용 가능한 디스크 블록을 찾기 위해 data bitmap을 읽습니다.
13. 사용 가능한 디스크 블록을 찾고 이제 bar를 위해 사용할 것이라고 표시해줍니다.
14. 할당받은 디스크 블록으로 가서 데이터를 write 합니다.
15. 디스크 블록에 write 작업을 끝내면 bar inode로 돌아와서 수정된 정보를 bar inode에 write 합니다.
/foo/bar의 크기가 12KB였기 때문에 13~15 부분이 3번 반복되게 되면 요청된 write작업을 완료하게 되고 끝난 뒤엔 close()를 호출하여 파일을 닫게 됩니다.
파일을 읽고 쓰는 과정을 살펴봤는데 어떤가요? 간단한 작업인줄알았는데 12KB 크기의 읽기 작업을 위해서는 14번의 disk I/O, 쓰기 작업을 위해서는 25번의 dist I/O가 발생합니다. Disk는 아주 느리기 때문에 이렇게 자주 접근하는 것은 비효율적이고 이를 줄이기 위한 방법이 필요할 것 같아요.
Caching and Buffering
방금전까지 알아본 대로 그냥 단순하게 읽고 쓰기를 진행하면 디스크 I/O가 너무 많이 발생합니다. 이는 곧 성능 저하로 이어지게 되고 이를 해결하기 위해 메모리를 활용하여 성능을 향상하려고 합니다.
첫 번째 방법은 Caching 방법입니다. 아까의 예제에선 읽으려는 파일이 /foo/bar 라는 짧은 경로를 갖고 있었기 때문에 그나마 I/O가 적게 발생했었는데요, 만약 /1/2/3/4/5/.../100과 같은 경로를 읽겠다고 하면 경로만 읽는데도 수백 번의 I/O가 발생하게 됩니다. 따라서 파일 시스템은 가상 메모리에서 알아본 LRU (Least Recently Used)와 같은 지역성을 활용한 방법으로 캐시를 활용하게 됩니다. 이러한 캐시는 부팅 시 메모리의 약 10% 부분을 차지한다고 합니다.

실제로 아까의 예에서 캐시를 사용하게되면 위와 같이 read를 줄일 수 있습니다. 위에선 write도 줄어드는 것을 볼 수 있는데 이는 캐시를 사용했기 때문이 아닌 두 번째 방법인 buffering 방법 때문입니다.
두 번째 방법인 buffering 방법은 버퍼링이라고 하시면 다들 어느 정도 감이 올 것 같습니다. 쓰기 작업을 할 때 매번 디스크에 쓰는 것이 아닌 어느 정도 쓰기 작업을 메모리에 모은 뒤 한 번에 쓴다는 아이디어입니다. 이는 delayed write(지연 쓰기)라고도 하며 이렇게 되면 쓰기 작업에 대한 디스크 I/O를 많이 줄여 성능을 향상할 수 있습니다.

아까의 예에서 캐싱과 버퍼링을 사용하면 위와 같이 I/O를 줄일 수 있는데요, 아까 보단 정말 많이 줄어든 것을 볼 수 있습니다. 이러한 지연 쓰기를 할 때 주의할 점은 얼마나 모았다가 쓸 것인가에 대한 내용인데요, 만약 메모리에 모으기만 하다가 정전이 나버리면 데이터가 모두 날아가 버리는 사고가 발생할 수 있습니다. 따라서 이러한 손실을 방지하기 위해 fsync()를 호출하거나 캐시 주변에서 작동하는 direct I/O 인터페이스를 사용할 수 있습니다.
Summary
이번 글에서는 파일 시스템을 구현하는데 필요한 기본적인 내용들을 살펴봤으며 inode와 여기에 저장되는 메타 데이터, 사용가능한 inode, disk block을 알려주는 bitmap도 알아봤습니다. 또한 이러한 구조를 갖는 파일 시스템에서 파일을 읽고 쓸 때의 흐름과 여기서 발생하는 문제점, 이를 해결하는 방법도 알아봤습니다. 다음 글에서는 Fast File System이라는 파일 시스템에 사용된 성능향상을 위한 여러 방법들에 대해 알아보도록 하겠습니다.
감사합니다!
'Computer > Operating System' 카테고리의 다른 글
| [OS] 파일시스템의 consistency(일관성)를 위한 FSCK, Journaling - OS 공부 30 (1) | 2021.02.24 |
|---|---|
| [OS] Fast File System의 File System 성능향상 아이디어 - OS 공부 29 (0) | 2021.02.17 |
| [OS] File과 Directory - OS 공부 27 (1) | 2021.02.06 |
| [OS] Redundant Arrays of Inexpensive Disks(RAID) 알아보기 - OS 공부 26 (1) | 2021.01.30 |
| [OS] Hard Disk Drive 알아보기 - OS 공부 25 (2) | 2021.01.23 |
- Total
- Today
- Yesterday
- document
- 동시성
- BFS
- Apple
- 프로그래밍
- OSTEP
- 백준
- IOS
- dfs
- 문법
- 앱개발
- Publisher
- OS
- 아이폰
- 알고리즘
- mac
- 스위프트
- Xcode
- DP
- Combine
- Swift
- 자료구조
- pattern
- System
- operator
- 코테
- 테이블뷰
- 코딩테스트
- design
- operating
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |