
티스토리 뷰
안녕하세요 Pingu입니다!
이번 글에서는 멀티 프로세서에서 스케줄링하는 방법에 대해 알아보겠습니다. 제가 공부할 때 참고하고 있는 OSTEP 책에선 Chapter 10 - Multi-CPU Scheduling 부분입니다. 이번에 다룰 부분은 나중에 배울 Concurrency(동시성)을 공부 한 뒤에 보는 것이 가장 좋다고 하네요. 나중에 동시성을 공부한 뒤에 다시 보도록 해야겠습니다.
Multiprocessor Scheduling (Advanced)
요즘 나오는 CPU에 멀티 코어, 쿼드 코어, 헥사 코어 등을 광고하는 것을 보신 적이 있으신가요? 이렇게 요즘엔 멀티 프로세서 시스템이 보편화되고 있습니다. 이러한 CPU에서는 어떻게 스케줄링을 해서 사용해야 할까요??
하나 이상의 CPU가 있으면 지금까지는 고려하지 않았던 몇 가지 문제가 발생할 수 있습니다. 가장 중요한 것은 일반적인 프로그램은 단일 CPU만 사용한다는 것입니다. 즉 이 말은 CPU가 여러 개라고 해서 하나의 프로그램이 더 빨리 실행되는 것은 아니라는 것이죠. 이러한 문제를 해결하려는 방법 중 하나는 스레드를 사용해서 병렬로 실행될 수 있도록 다시 설계해야 합니다. 이렇게 만든 다중 스레드 프로그램은 수행해야 하는 작업을 여러 CPU에 나눠서 실행할 수 있기 때문에 CPU가 여러 개라면 더 빠르게 실행될 수 있습니다. 다른 방법으로는 멀티 프로세서에서 사용할 수 있는 스케줄러를 사용하는 것입니다. 지금까지 알아본 스케줄링들은 모두 단일 프로세서라고 가정하고 알아봤었습니다. 이번 글에서는 두 번째 방법인 스케줄러를 사용하여 멀티 프로세서를 사용하는 방법에 대해 알아보겠습니다.
Background: Multiprocessor Architecture
우선 멀티 프로세서에 대해 알아보겠습니다. 우선 싱글 프로세서와 멀티 프로세서의 근본적인 차이에 대해 알아보겠습니다.
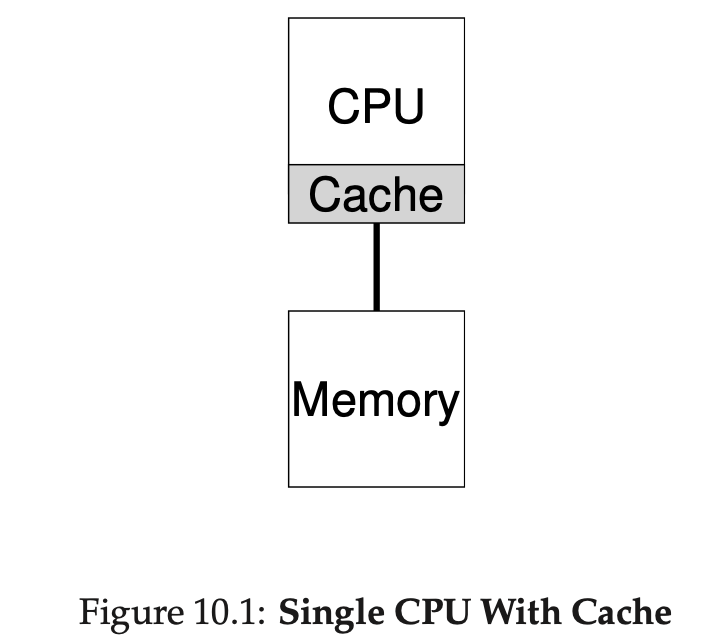
CPU에는 아주 빠른 Cache가 있습니다. 위와 같이 싱글 프로세서에는 하나의 캐시가 존재합니다. 캐시에는 메인 메모리에 있는 현재 프로그램에서 자주 사용되는 데이터들이 저장되어 있습니다. 자주 사용되는 데이터를 아주 빠른 캐시에 저장해둠으로써 비교적 느린 메모리를 빠른 것처럼 보이게 할 수 있습니다. 예를 들면 어떤 프로그램에서 필요한 데이터를 메인 메모리에서 가지고 온다고 가정하겠습니다. 메모리는 느리기 때문에 아주 오랜 시간이 걸려서 데이터를 가져오게 됩니다. 그런데 다음에 동일한 데이터를 또다시 메모리에서 가지고 온다고 한다면 어떨까요? 매번 느린 메모리에서 데이터를 가지고 오는 것이 마음에 들진 않습니다. 따라서 자주 사용될 것 같은 데이터를 캐시에 저장해둬서 해당 데이터가 필요할 때마다 빠르게 가지고 옴으로써 훨씬 더 빠르게 실행되게 만들어 줍니다.
그렇다면 캐시에는 어떤 데이터가 저장되는 것이 효과적일까요? 이는 Locality라고 하는 개념이 해결해줍니다. 지역성이라고 하는 이 특성은 Temporal(시간) 지역성과 Spatial(공간) 지역성이 있습니다. 시간 지역성이란 지금 사용한 데이터는 곧 다시 사용될 가능성이 높다는 개념입니다. 공간 지역성은 어떤 데이터가 사용되었다면 그 근처에 존재하는 데이터들도 사용될 가능성이 높다는 개념입니다. 이러한 지역성이라는 특성을 활용해서 캐시에 데이터를 저장할 수 있습니다.
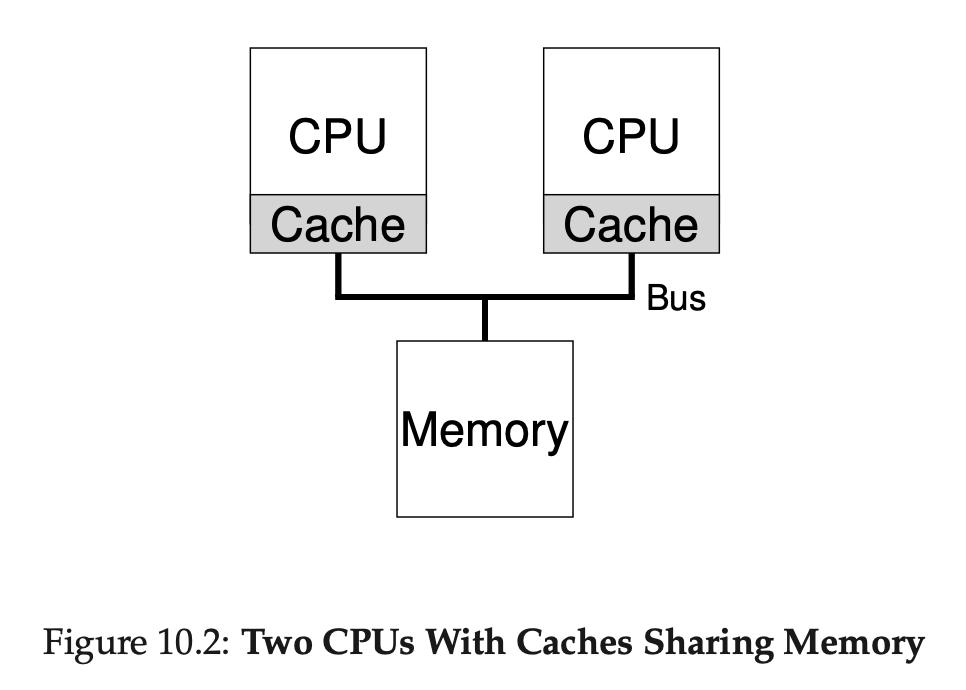
그러면 이제 위와 같이 하나의 메모리를 공유하는 시스템에 프로세서가 여러 개라면 어떻게 될까요? CPU가 여러 개가 되었기 때문에 캐시도 여러개가 된 것을 볼 수 있습니다. CPU가 2개 있는 위와 같은 시스템에서 프로그램을 동작하는 예를 보겠습니다. CPU 1에서 실행되는 프로그램이 메모리에서 A 데이터를 가지고 왔습니다. 이때 가지고 온 A 데이터를 수정해서 CPU1 캐시에 씁니다. 근데 컴퓨터는 메모리에 수정된 값을 바로 저장하지 않습니다. 이는 메모리는 너무 느리기 때문에 최대한 적게 접근하려고 하기 때문인데요. 이렇게 수정된 값을 메모리에 바로 적용하지 않는 것을 delayed write라고 합니다. 어쨌든 그런 뒤 동일한 프로그램을 이제는 CPU 2에서 실행합니다. A라는 데이터가 필요해 메모리에서 가지고 옵니다. 그럼 이 때 가져온 A라는 데이터는 이미 CPU 1에서 가져와서 수정이 되었는데도 불구하고 수정되지 않은 데이터를 가지고 온 셈입니다. 어떤가요 큰 문제 같지 않나요? 이러한 문제를 cache coherence(캐시 일관성)이라고 합니다. 이런 문제는 어떻게 해결할 수 있을까요?
가장 기본적인 해결방법은 하드웨어에 의해 제공됩니다. 메모리 접근을 모니터링하는 것입니다. 각각의 캐시는 메인 메모리에 연결한 버스를 관찰하고 메모리 업데이트를 관찰합니다. 그런 뒤 CPU가 캐시에서 데이터를 수정하면 그것을 인식하여 나중에 메모리가 캐시에서 수정된 데이터를 가져올 때 적절히 처리할 수 있도록 합니다.
Don't Forget Synchronization
캐시가 일관성을 제공하기 위해 아까 언급한 방법을 수행한다고 할 때 프로그램이 공유 데이터에 접근할 때는 어떤 것을 걱정해야 할까요? 이번 섹션에서는 동시성에 대해서 알고 있다고 가정하고 간단하게 짚고 넘어가 보겠습니다.
CPU에서 공유 데이터에 접근할 때 상호 배제(Lock 등)를 사용하여 정확성을 보장해줘야 합니다. 예를 들어 여러 CPU에서 동시에 데이터에 접근하는 경우 Lock이 없다면 데이터가 어떻게 변해있을지 예상할 수 없습니다. 예를 들어 CPU 1과 CPU 2가 동시에 5라는 데이터에 접근했다고 생각하겠습니다. 그런 뒤 CPU 1은 5를 1로 바꾸고 CPU 2는 5를 2로 바꿨다고 보겠습니다. 그럼 현재 데이터는 어떤 값을 가지고 있을까요? 만약 1이 저장되어 있다면 CPU 2의 입장에서는 당황스럽지 않을까요? 이렇게 일관성을 보장할 수 없기 때문에 Lock이라는 개념이 필요합니다. 이는 나중에 동시성 단원에서 다시 살펴보겠습니다!
One Final Issue: Cache Affinity
마지막 문제는 Cache Affinity(캐시 선호도)입니다. 특정 CPU에서 프로그램을 수행하면 해당 프로그램은 해당 CPU의 캐시에 여러 가지 데이터를 저장합니다. 다음에 다시 수행될 때 캐시에 저장된 정보를 가지고 더 빠르게 수행할 수 있죠. 하지만 만약 CPU가 여러 개라서 다음에 수행될 때 다른 CPU에서 수행된다면 어떻게 될까요? 또다시 필요한 데이터를 가지고 와야 하는 문제가 발생합니다. 즉 성능이 나빠지는 것이죠. 따라서 멀티 프로세서에서의 스케줄러는 프로그램을 스케줄링할 때 캐시 선호도를 고려해서 프로그램을 동일한 CPU에서 계속 실행되도록 해줘야 합니다.
Single-Queue Scheduling
그럼 이제 지금까지 알아본 문제와 배경지식을 바탕으로 멀티 프로세서에서 스케줄링을 사용하는 방법에 대해 알아보겠습니다! 가장 쉬운 방법으로 이전의 글들에서 살펴본 스케줄링 방법들을 그대로 사용하는 것입니다. 즉 싱글 프로세서에서 쓰던 스케줄러를 그대로 사용하는 것이죠. 하나의 큐에 작업들을 넣어서 처리하는 이러한 방법을 SQMS(Single Queue Multprocessor Scheduling)이라고 합니다. 이 방법은 단순하다는 장점이 있습니다.
하지만 SQMS에는 큰 문제들이 존재합니다. 첫 번째 문제는 a lack of saclability(확장성 부족)입니다. 스케줄러가 여러 CPU에서 잘 작동하는지 확인하기 위해 아까 위에서 Lock을 사용한다고 했었습니다. 하지만 Lock을 사용하면 성능을 크게 저하시킬 수 있습니다. 실제로 이렇게 사용하게 되면 실제 프로그램 수행 시간보다 Lock을 처리하는 작업에 더 많은 시간을 사용할 수도 있습니다.
두 번째 문제는 아까 살펴본 캐시 선호도입니다. 이는 예를 보며 알아보겠습니다.
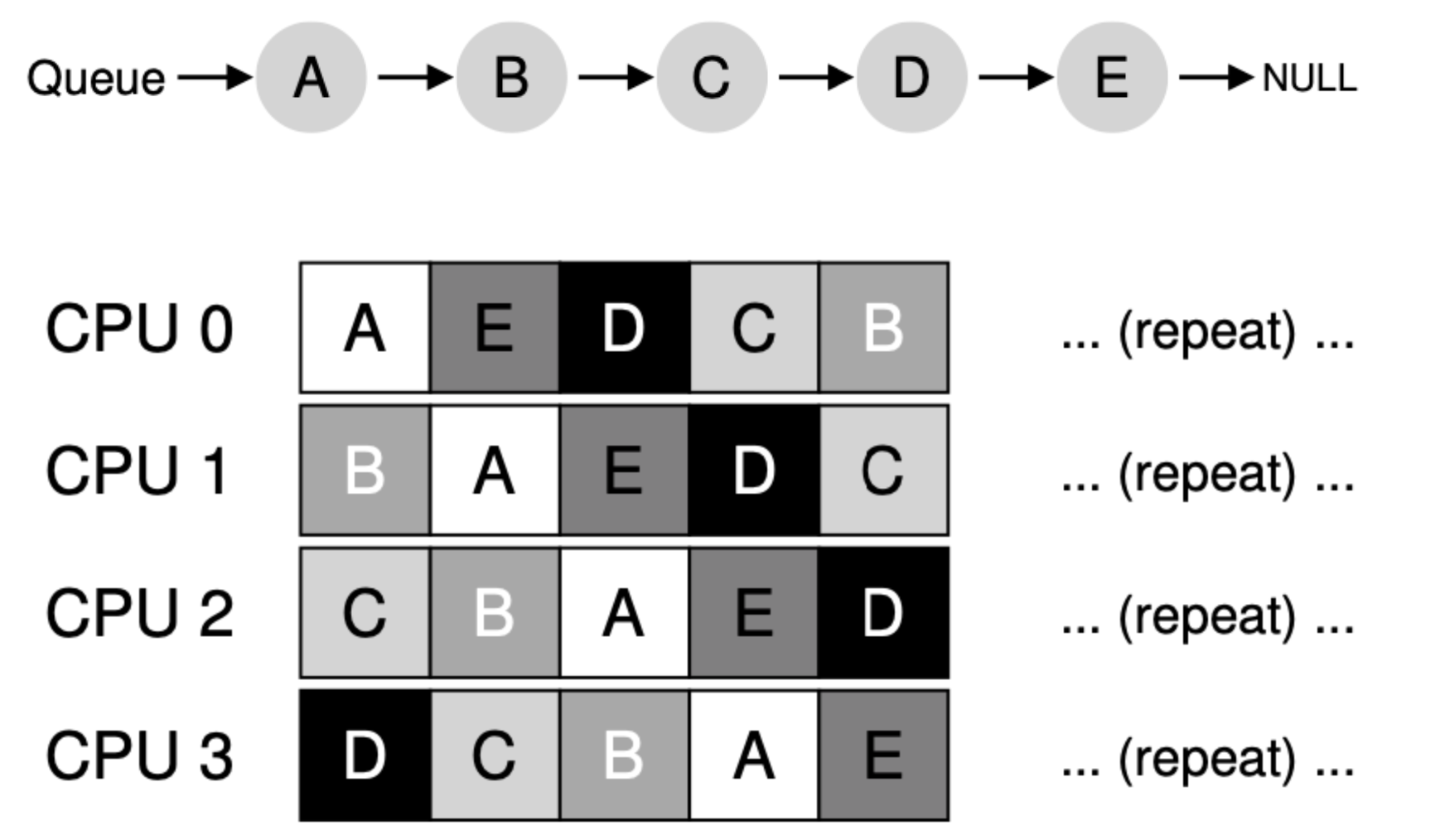
위와 같이 큐가 있고 CPU는 4개가 있다고 가정하겠습니다. 순서대로 수행된다면 어떻게 될까요? A 프로세스를 기준으로 보겠습니다. A가 CPU0에서 time slice를 모두 사용해서 Ready 상태로 돌아갔다고 보겠습니다. 그런 뒤 다음 스케줄링될 때 CPU1에서 수행된다고 한다면 캐시 친화도가 전혀 적용되지 않는 것을 볼 수 있습니다.
이러한 문제를 해결하기 위해서 SQMS에서는 별도의 메커니즘을 사용해서 캐시 친화도를 구현합니다.
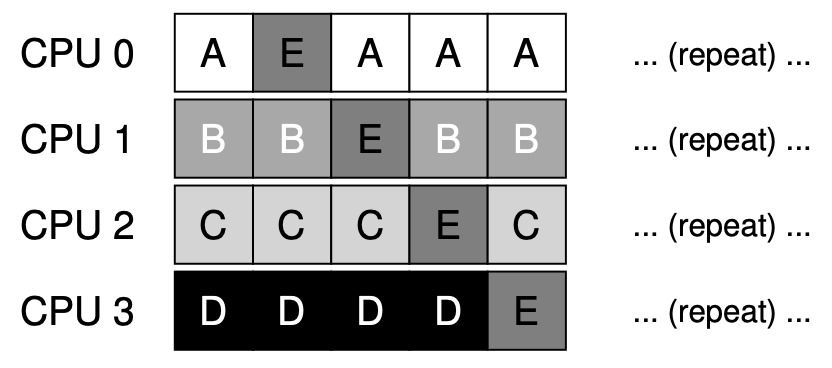
위와 같이 SQMS에서는 캐시 친화도를 구현합니다. 그런데 E 프로세스의 입장에서 보면 캐시 친화도가 전혀 적용되고 있지 않습니다. 이와 같이 SQMS에서는 캐시 친화도가 적용되는 프로세스도 있는 반면 적용되지 않는 프로세스가 존재할 수 있습니다. 그렇다면 지금 알아보고 있는 이 문제 많은 SQMS가 최선일까요??
Multi-Queue Scheduling
그럼 이번 섹션에서는 알아본 SQMS에서의 문제점을 보완한 MQMS(Multi Queue Multiprocessor Scheduling)에 대해 알아보겠습니다. 이름부터 알 수 있듯이 아까의 SQMS와의 차이점은 큐가 여러 개라는 것입니다. CPU는 각각 하나 또는 그 이상의 가지며 각각의 큐는 RR과 같은 특정한 스케줄링 방법을 사용합니다. 작업이 시스템에 들어오면 heuristic에 따라 하나의 큐에만 배치가 됩니다. 그런 뒤에는 CPU 독립적으로 스케줄링되기 때문에 SQMS에서 발생한 문제들을 방지할 수 있습니다. 예를 보며 이해해보겠습니다.
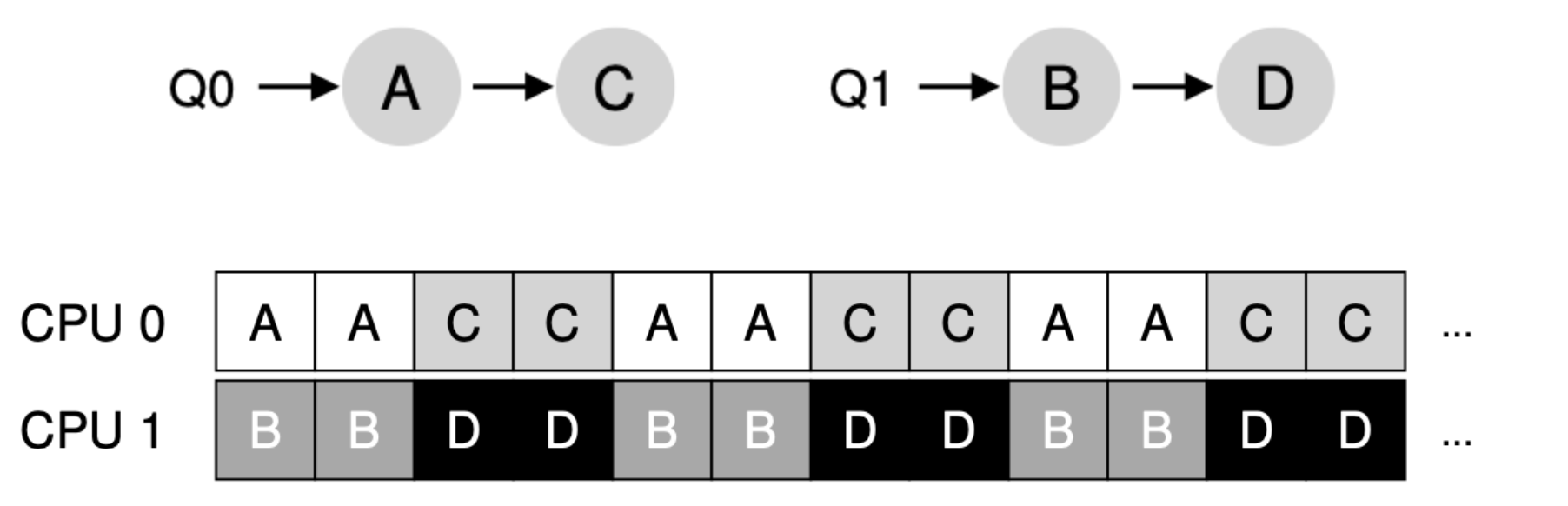
위와 같이 2개의 CPU가 존재하며 각각의 CPU에 개별적으로 큐가 존재한다고 보겠습니다. CPU는 자신이 처리할 큐에 있는 작업들만 처리하므로 위와 같이 캐시 친화도가 잘 적용됩니다. 그렇다면 지금의 MQMS에는 문제점이 없을까요? 음... 아닐 거 같습니다. 지금은 큐에 있는 작업수가 같았고 모두 완료가 되지 않아서 문제가 발생하지 않았지만 다른 예에서는 어떨까요?
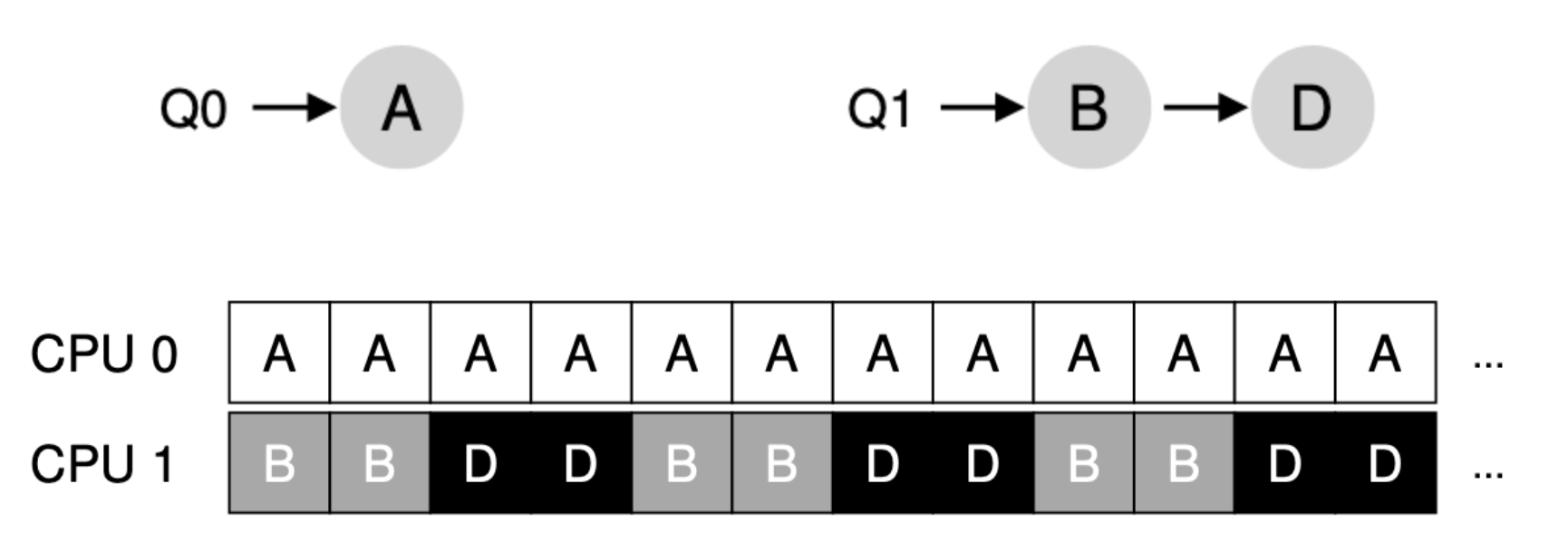
위의 예를 보겠습니다. 아까의 예에서 Q0에 있던 C 프로세스가 완료된 상태입니다. 문제점이 보이시나요? A 프로세스가 CPU를 독점하고 있습니다. 이는 B, D 입장에서 보면 A가 운이 좋아서 저렇게 많이 수행되나 보다 하고 넘어갈 수도 있지만 보통 화를 냅니다. 아니 왜 쟤만 많이 실행해? 라면서 요. 그럼 더 극단적인 상황을 한 번 볼까요?
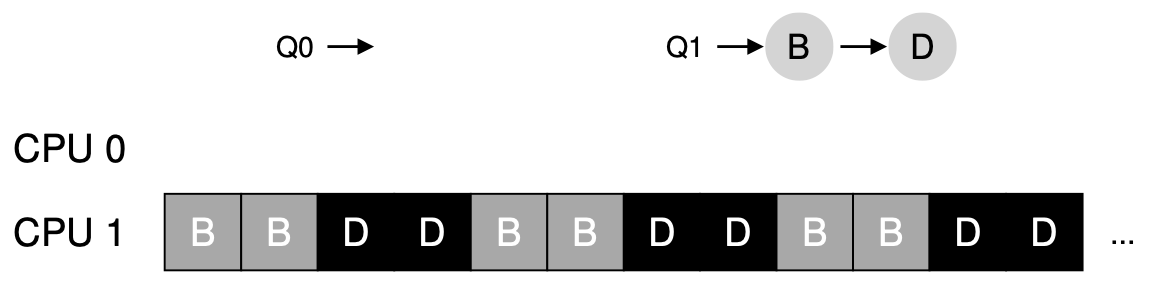
이젠 라인 잘 탄 A마저 완료되어 Q0에는 작업이 더 이상 없습니다. CPU0가 놀고 있네요. 이제는 B, D 프로세스가 화를 내는 것이 아닌 사용자도 화를 냅니다. 아니 왜 저 CPU는 쉬는거지?라면서요. 이러한 문제를 load imbalance(부하 불균형)이라고 합니다. 어떻게 하면 이런 문제를 해결할 수 있을까요?
아주 간단하게 생각하면 B,D 프로세스 중 하나를 Q0로 옮기는 것입니다. 이러한 것을 migration이라고 합니다. 이렇게 프로세스를 이동하면 load balance를 만족시킬 수 있습니다. 예를 보며 migration을 살펴보겠습니다.

즉 이 상태에서 Q1에 있는 B,D 중 하나를 Q0로 옮겨주면 끝입니다. 그럼 이런 경우는 어떨까요?
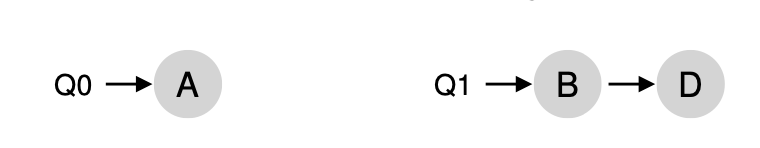
위와 같은 경우에서는 B,D 중 하나를 옮긴다고 해서 해결될 거 같진 않습니다. 그 이유는 옮기는 순간 Q1에서 또 문제가 발생하기 때문이죠. 이런 문제는 어떻게 해결하면 좋을까요? 답은 계속 이동하는 것입니다. B를 이동시켰다가 A도 이동시켰다가 하는 등 프로세스들을 계속 이동시키는 것이죠, 그럼 결국 아래와 같이 수행될 겁니다.

이렇게 하면 load balance가 지켜집니다. 이렇게 프로세스를 이동할 때 무엇을 어디로 이동할지 결정하는 방법에는 work stealing(작업 훔치기)가 있습니다. 이는 작업이 적은 큐가 다른 큐를 보고 작업이 많아 보이면 작업을 훔쳐버립니다.
그런데 이렇게 작업을 훔쳐가면서까지 load balance를 맞추려고 하다 보면 근본적인 문제에 부딪히게 됩니다. 애초에 저희가 SQMS에서 Lock에 의한 오버헤드가 발생했고 확장 문제가 발생해서 MQMS로 넘어왔는데 너무 자주 작업을 훔치게 되면 이러한 문제를 동일하게 발생합니다. 그렇다고 훔치지 않으면 load balance에 문제가 발생하므로 이 둘을 잘 조율할 수 있는 값을 찾는 것이 현재 숙제입니다.
Linux-Multiprocessor Schedulers
실제 리눅스에서는 O(1) 스케줄러, 이전 글에서 살펴본 CFS, 그리고 BFS라는 스케줄러가 사용되었습니다.
O(1), CFS는 모두 여러 개의 큐를 사용하는데 비해 BFS는 하나의 큐만 사용합니다. 이를 통해 SQMS, MQMS 모두 사용할 수 있다는 것을 보여줍니다. 물론 훨씬 더 복잡한 방법으로 구현이 되어 있습니다. 예를 들어 O(1)은 이전에 알아본 MLFQ와 유사한 우선순위 기반 스케줄러로 가장 높은 순위에 있는 스케줄러를 스케줄링합니다. CFS는 deterministic proportional-share 접근방식이었습니다. 세 가지 스케줄러 중 유일한 단일 큐 방식인 BFS도 proportional-share이지만 EEVDF(Earliest Eligible Virtual Deadline First)라는 방법으로 동작합니다. 이러한 최신 알고리즘에 대해서도 나중에 공부해야 할 것 같습니다.
Summary
이번 글에서는 멀티 프로세서 시스템에서의 스케줄링 방법에 대한 다양한 접근 방식을 알아보았습니다. SQMS는 단순하지만 캐시 선호도 문제와 Lock에 의한 오버헤드라는 문제가 있었습니다. MQMS는 확장성이 뛰어나고 캐시 선호도를 잘 처리하지만, load imbalance라는 문제를 발생했고 SQMS보다 복잡했습니다.
멀티 프로세서에서의 스케줄링 방법에 대한 방법을 이해하시는데 도움이 되셨길 바랍니다!!
다음 글 부터는 메모리 가상화에 대해 알아보도록 하겠습니다.
감사합니다.
'Computer > Operating System' 카테고리의 다른 글
| [OS] C언어에서 메모리를 사용 하기 위한 Memory API - OS 공부 8 (2) | 2020.12.12 |
|---|---|
| [OS] 메모리 가상화를 위한 메모리 추상화, 주소 공간 (Abstraction, Address Space) - OS 공부 7 (0) | 2020.10.22 |
| [OS] 공평한 스케줄러 만드는 법 (Proportional Share) - OS 공부 5 (4) | 2020.10.18 |
| [OS] MLFQ(Multi Level Feedback Queue) 스케줄링 방법 - OS 공부 4 (5) | 2020.10.17 |
| [OS] 프로세스를 스케줄링 하는 방법들 (Scheduling) - OS 공부 3 (0) | 2020.10.16 |
- Total
- Today
- Yesterday
- BFS
- 동시성
- 앱개발
- 자료구조
- Publisher
- document
- operating
- mac
- design
- System
- 코딩테스트
- 스위프트
- 문법
- IOS
- 테이블뷰
- Swift
- pattern
- 알고리즘
- dfs
- Apple
- 백준
- OS
- Xcode
- Combine
- DP
- 코테
- 아이폰
- 프로그래밍
- OSTEP
- operator
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |