
티스토리 뷰
[OS] MLFQ(Multi Level Feedback Queue) 스케줄링 방법 - OS 공부 4
Dev_Pingu 2020. 10. 17. 18:17안녕하세요 Pingu입니다!
이번 글에서는 저번 글에 이어 운영체제에서 프로세스를 실행할 순서를 설계하는 Scheduling(이하 스케줄링)에 대해 알아보려고 합니다! 제가 공부할 때 참고하고 있는 OSTEP 책에선 Chapter 8 - Multi Level Feedback Queue 부분입니다.
Multi-Level Feedback Queue
저번 글에서는 FIFO, SJF, STCF, RR와 같은 방법들을 알아봤습니다. SJF, STCF는 Turnaround Time이 좋지만 이를 사용하기 위해서는 프로세스의 수행 시간을 알고 있어야 했지만 알 수 없었습니다. RR과 같은 경우에는 Response Time은 좋지만 Turnaround Time은 아주 나쁜 성능을 보였습니다. 이런 문제들을 해결하기 위해 이번 글에서 소개할 스케줄링 방법이 MLFQ(Multi Level Feedback Queue)입니다!
MLFQ는 F.Corbato라는 분이 개발하셨고 이 분은 MLFQ로 Turing Award를 받았다고 합니다. 이번 글에서는 MLFQ를 사용하여 실행할 프로세스에 대해 아무 정보도 없는 경우에도 스케줄링을 효율적으로 할 수 있도록 하고 프로세스가 과거에 수행된 적이 있다면 그러한 정보를 토대로 더 나은 스케줄링을 할 수 있는 방법을 알아보겠습니다.
MLFQ: Basic Rules
MLFQ는 몇 가지 특징을 가지고 있습니다.
- 여러 개의 큐를 가지고 있다.
- 각 큐는 서로 다른 우선순위를 갖는다.
- Ready 상태인 모든 프로세스들은 어떤 큐 안에 들어있다.
두 작업이 서로 다른 큐에 들어있다면 우선순위가 높은 큐에 들어있는 작업부터 수행합니다. 그럼 만약 동일한 큐에 두 개의 작업이 있다면 어떻게 될까요? 이 때는 두 작업의 우선순위가 동일하기 때문에 두 작업 간에 RoundRobin 스케줄링을 사용하여 수행하게 됩니다. 앞의 예를 근거해서 저희는 이러한 규칙을 만들 수 있습니다.
- 규칙 1 : 우선순위가 높은 프로세스들을 먼저 수행한다.
- 규칙 2 : 작업들이 같은 우선순위를 갖는다면 RR로 수행한다.
따라서 MLFQ 스케줄링의 핵심은 우선순위를 설정하는 방법이라고 볼 수 있습니다! MLFQ는 작업에게 한 번 우선순위를 설정하는 것이 아닌 과거의 실행에 따라 작업의 우선순위를 바꿔줍니다. 예를 들어 어떤 작업이 I/O 작업을 계속 발생한다고 가정하겠습니다. 이 때는 MLFQ 스케줄러가 이 작업이 대화형 프로그램이라고 판단하여 우선순위를 높게 설정합니다. 그러다 잠시 후 동일한 작업이 더 이상 I/O를 발생하지 않고 CPU만 계속 사용한다면 MLFQ는 다시 우선순위를 낮게 설정해줍니다. 이렇게 우선순위를 변경해주지 않으면 어떤 문제가 발생할까요? 그럼 이번에는 MLFQ가 우선순위를 변경하지 않을 때 동작하는 예를 보고 문제점을 알아보겠습니다.
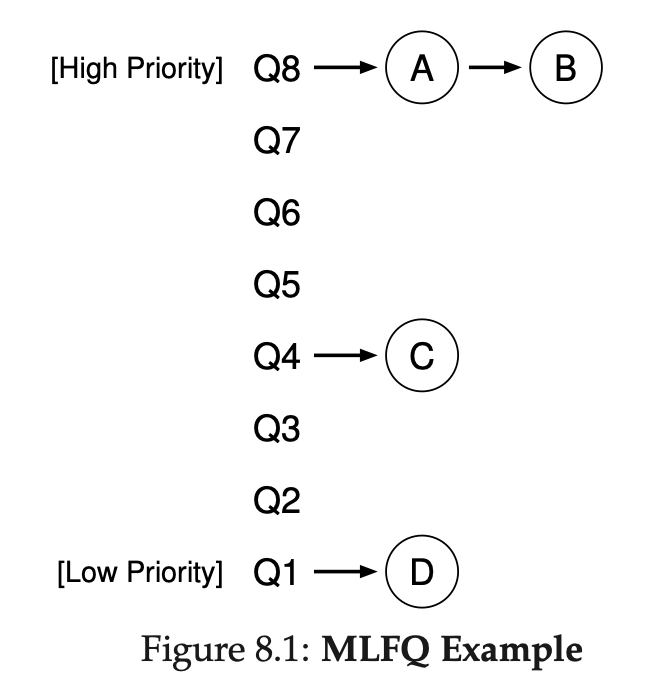
위의 그림을 보면 Q8에 A, B 프로세스, Q4에 C 프로세스, Q1에 D 프로세스가 존재합니다. MLFQ는 우선순위에 따라 스케줄링한다고 했으니 A, B가 가장 먼저 RR방식으로 수행될겁니다. 그렇다는 것은 A, B가 완료 될 때 까지는 C, D는 스케줄링이 되지 않는다는 말입니다. 만약 A,B가 아주 오래 걸리는 작업이라면 C, D의 Response Time은 급격히 나빠질거에요. 저희가 MLFQ를 사용하는 이유가 사라지는 것이죠. 그럼 이런 문제를 해결하기 위해 우선순위를 상황에 따라 변경해줘야 하는데 어떻게 변경해줘야할지 다음 섹션에서 알아보겠습니다.
Attemp #1: How To Change Priority
이제 저희는 MLFQ가 작업들의 우선순위를 변경해줘야하는 필요성을 알았습니다! 그럼 어떻게 바꿔주는 게 좋을까요? 어떻게 우선순위를 변경할지를 결정하기 위해 workload를 고려해야 합니다. 즉 대화형 작업이냐 그냥 CPU만 사용하는 작업이냐를 알아야 하는 것이죠. 이를 고려해서 우선순위를 정하는 규칙들을 간단하게 MLFQ의 규칙들에 추가해보겠습니다!
- 규칙 3 : 새로운 프로세스가 시스템에 들어가면 가장 높은 우선순위를 부여한다.
- 규칙 4a : 작업이 실행될 때 time slice를 모두 사용하면 우선순위를 감소시킵니다.
- 규칙 4b : 작업이 실행 될 때 time slice를 모두 사용하지 않고 CPU를 포기하면 우선순위를 그대로 유지합니다.
여기서 우선순위를 감소시키거나 유지한다는 말은 프로세스가 속한 큐의 위치를 뜻합니다. 아까의 예를 다시 보겠습니다.
위의 그림에서 가장 먼저 A, B가 RR로 수행되는데 A, B가 설정한 time slice를 모두 사용했다면 우선순위를 감소시킵니다. 즉 Q7~Q1 사이의 큐로 이동하는 것이죠! Time slice를 모두 사용하지 않고 CPU를 포기한다면 그대로 Q8에 위치시킵니다. 이렇게 CPU를 포기하는 작업들은 주로 I/O 작업을 포함한 프로세스입니다.
이러한 규칙들을 만든 결과를 이렇게 정리할 수 있습니다. MLFQ에서는 작업의 우선순위가 고정되어있지 않으며 우선순위는 과거의 행동에 기반해 변경한다. 즉 MLFQ에 왜 Feedback이 들어있는지 알 수 있는 사실입니다! 그리고 어떤 작업이 I/O 작업이 많은 대화형 작업이라면 우선순위를 계속 높게 유지하고 CPU를 많이 사용하는 작업이라면 우선순위를 점점 낮게 변경하게 됩니다. 즉 Batch작업이냐 Interactive 작업이냐에 따라 우선순위를 변경할 수 있게 됩니다!
그럼 이런 규칙들이 잘 정해진 규칙인지 예를 보며 확인해보겠습니다.

위의 그림의 예는 큐가 3개 일 때 어떤 하나의 작업이 어떻게 수행되는지 보여주는 그림입니다. 위의 예에서 time slice는 10초라고 설정되었습니다. 처음 작업이 들어오게 되면 규칙 3에 의해 우선순위가 가장 높은 큐에 위치하게 됩니다. 위의 예에서는 Q2입니다. 거기서 10초를 수행하면 주어진 timeslice를 모두 사용하였기 때문에 우선순위가 낮은 Q1으로 이동합니다. 10초를 더 수행한 뒤엔 결국 가장 낮은 우선순위인 Q0으로 이동하게 됩니다. 아직까진 규칙들을 잘 만든 거 같아요! 그럼 좀 더 복잡한 예를 살펴보겠습니다.

위의 그림의 예는 아까보다는 좀 더 복잡하게 작업이 2개가 존재합니다. 편의상 A, B라고 제가 이름을 붙였습니다. 아까와 time slice는 10초로 동일하고 새로 들어오는 B 작업은 20초가 걸리는 작업이라고 가정하겠습니다. A 작업은 100초까지는 아까와 동일하게 동작합니다. 그런데 100초에서 B작업이 새로 들어오게 되고 규칙 3에 의해 새로운 작업은 가장 높은 우선순위를 가지게 됩니다. 따라서 A를 중단하고 B를 수행하게 됩니다. B작업이 time slice 2번만큼 동작하는 짧은 작업이었기 때문에 Q1에서 완료하게 됩니다. 이렇게 B작업이 위의 그림처럼 비교적 짧은 작업이라 빨리 끝나게 된다면 SJF와 비슷하게 동작하게 됩니다. 반면에 B작업이 많이 오래 걸리는 작업이었다면 결국 Q0까지 내려와서 A, B는 RR로 작동하게 될 것입니다. 그럼 이번에는 I/O 작업이 있는 예를 보겠습니다.

위의 그림의 예는 아까와 time slice는 동일하고 A, B 작업의 수행 시간도 동일합니다. 한 가지 다른 점은 B 작업이 1초씩 수행하고 I/O를 수행한다는 점입니다. 아까 규칙 4b에서 정의한 대로 B작업은 10초의 time slice를 수행하기 전에 I/O를 요청하기 때문에 우선순위가 변하지 않고 그대로 인 것을 볼 수 있습니다. 그러므로 B의 I/O가 처리되면 A보다 반드시 먼저 수행될 수 있게 스케줄링되는 것이죠. 어떤가요? 규칙들이 잘 정의된 것 같나요? 지금까지 예들만 보면 규칙들이 잘 정의된 것 같습니다! 모든 작업들이 수행 시간이 긴 작업이라면 공평하게 수행될 수 있으며 짧게 수행되는 작업이거나 I/O 작업일 경우에 우선순위를 높게 유지하여 빨리 수행될 수 있도록 합니다. 아주 좋아 보입니다! 하지만.. 저희가 만든 규칙들을 교묘하게 피해 가는 방법들이 있습니다. 이렇게 교묘하게 규칙들을 피해 가면 아주 큰 문제를 발생합니다.
먼저 starvation(기아) 문제가 있습니다. 기아 문제란 어떤 작업이 오랫동안 수행이 안 되는 상태를 말합니다. 예를 들어 아까 예에서는 A, B의 두 작업만 있었고 B작업만 I/O를 발생했습니다. 만약 B작업과 같은 대화형 작업이 엄청나게 많다면 어떻게 될까요? A는 아마 그런 작업들이 모두 수행되기 전까지는 수행될 수 없을 것입니다.
다음 문제는 프로세스가 스케줄러를 속여가며 계속 우선순위를 높게 유지하는 것입니다. 아까의 예도 비슷한 부분을 보이는데 더욱 극단적으로 10초의 time slice로 설정된 스케줄러에서 9.9초 동안 수행되고 I/O 작업을 발생시킨다고 생각해보겠습니다. 그럼 정말 너무 얄밉게도 계속해서 높은 우선순위를 유지할 수 있습니다. 정말 필요로 해서 I/O를 실행하는 것이 아닌 CPU 점유를 위해서 이를 악용한다면 문제를 발생할 수 있습니다.
마지막으로 프로그램이 수행되는 동안 특성이 변할 수 있다는 점입니다. 만약 100초까지는 CPU만 사용하던 작업이라 우선순위를 낮춰놨었는데 갑자기 100초부터 I/O를 실행하려고 하며 대화형 작업으로 변화한다면 어떻게 해야 할까요? 다시 우선순위를 올릴 방법이 아직은 없기 때문에 계속해서 낮은 우선순위를 유지하게 될 것이고 이는 Response Time에 문제를 발생합니다.
이런 문제들을 해결하기 위해서는 어떻게 해야할까요? 다음 섹션에서 해결방법을 같이 살펴보겠습니다!
Attemp #2: The Priority Boost
아까 발생한 문제 중 첫 번째인 기아 문제를 해결해보겠습니다. 기아 문제는 어떤 작업이 아주 오랫동안 실행되지 않는 문제였습니다. 이를 해결하기 위해서는 어떻게 하면 될까요? 아주 간단하게 오래동안 실행되지 않은 작업의 우선순위를 올려주면 됩니다. 어떤 작업이 오래동안 실행되지 않았는지 알아내기 귀찮으니 그냥 모든 작업의 우선순위를 주기적으로 가장 높게 만들어 주겠습니다. 그러기 위해서 새로운 규칙을 정의하겠습니다.
- 규칙 5 : 일정 시간 후 시스템의 모든 작업을 우선순위가 가장 높은 큐로 이동한다.
이러한 규칙을 Priority Boost라고 합니다.
사실 기아 문제를 해결하려고 이런 규칙을 만들었지만 사실 세 번째 문제였던 프로그램이 수행되던 중 특성이 변하는 문제도 해결할 수 있습니다. 프로그램이 CPU만 사용하길래 최하위 우선순위에 두었는데 갑자기 I/O를 사용할 때 이번에 만든 규칙을 적용하면 일정 시간 뒤에 우선순위가 높아지기 때문에 문제를 해결할 수 있습니다!
그럼 다시 기아 문제로 돌아와서 한 가지 예를 보며 문제가 해결되는지 살펴보겠습니다.

위의 그림에서 왼쪽이 priority boost를 적용하지 않은 상황이고 오른쪽이 50초마다 prioirty boost를 적용한 상황입니다. 왼쪽 그림에서는 아까 말한 문제대로 A 작업이 100초부터 실행되지 않는 것을 볼 수 있습니다. 이와 반대로 priority boost를 적용한 오른쪽에서는 50초마다 모든 작업의 우선순위를 우선순위가 가장 높은 큐인 Q2로 이동시키며 A도 수행할 수 있도록 만들어주는 것을 볼 수 있습니다. 여기서 몇 초마다 boost를 해줄 것인가에 대한 의문이 생기지 않나요? 너무 길게 설정하면 기아 상태의 지속시간이 비교적 짧아질 뿐이고 너무 짧게 설정하면 대화형 작업이 CPU 시간을 제대로 할당받지 못할 수 있습니다.
Attemp #3: Better Accounting
그럼 이제 남은 문제는 두 번째 문제였던 프로세스가 스케줄러를 속일 수 있던 문제입니다. 책에서는 이러한 문제를 gaming of our schedular라고 표현합니다. 예를 들어 10초의 time slice를 가진 스케줄러에서 의도적으로 9.9초마다 CPU를 포기하는 작업이 들어온다면 해당 작업은 계속해서 높은 우선순위를 유지하게 될 거예요. 이를 해결하기 위해 아까 만든 규칙 4a, 규칙 4b를 통합하여 새로운 규칙을 정의하겠습니다.
- 규칙 4 : 작업은 모든 우선순위에서 주어진 time slice를 모두 사용하면 우선순위가 감소한다.
이렇게 규칙을 정의하게 되면 9.9초를 수행하고 CPU를 포기해도 다음에 수행될 때는 0.1초만 수행되고 우선순위가 감소하게 됩니다. 그럼 새로 만든 규칙을 적용하면 어떻게 문제가 해결되는지 살펴보겠습니다.

위의 그림에서 왼쪽이 기존의 규칙을 적용한 상황이고 오른쪽이 새로운 규칙을 정의한 상황입니다. 왼쪽 그림에서는 B가 아주 교묘하게 time slice보다 적은 시간 동안 실행하다 CPU를 포기하며 우선순위를 유지하는 것을 볼 수 있습니다. 따라서 B가 모두 수행될 때까지 A 작업은 공평하게 수행될 수 없습니다. 그럼 이젠 새로운 규칙을 정의한 오른쪽 그림을 보겠습니다. 오른쪽 그림에서는 B가 치사하게 또 CPU를 time slice보다 적게 사용하고 포기했지만 이후에 수행될 때 전에 사용한 시간이 누적되었기 때문에 결국 우선순위가 낮아지는 것을 볼 수 있습니다. 그러다 결국 가장 우선순위가 낮은 Q0까지 내려와서 A, B는 동일한 우선순위를 갖게 됩니다.
이렇게 아까 발생한 문제들을 모두 해결할 수 있었습니다!
Tuning MLFQ And Other Issues
아까 발생한 문제들은 모두 해결했지만 이제는 해결한 방법에 대한 최적화와 구현의 문제를 생각할 때입니다. 예를 들어 priority boost에서는 몇 초마다 작업들의 우선순위를 증가할 것인가에 대한 문제가 남아있습니다. 큐의 개수는 몇 개로 만들 것인지도 문제입니다. 또한 time slice는 얼마로 해야 하는지도 고려해야 하는 문제입니다. 이를 해결하는 방법을 살펴보겠습니다.
먼저 실제 사용하는 MLFQ는 큐의 우선순위에 따라 time slice의 크기를 다르게 설정합니다. 높은 우선순위를 가진 큐의 경우 time slice를 짧게 설정하고 낮은 우선순위를 가진 큐의 경우 time slice를 길게 설정합니다. 예를 보며 이해해보겠습니다.
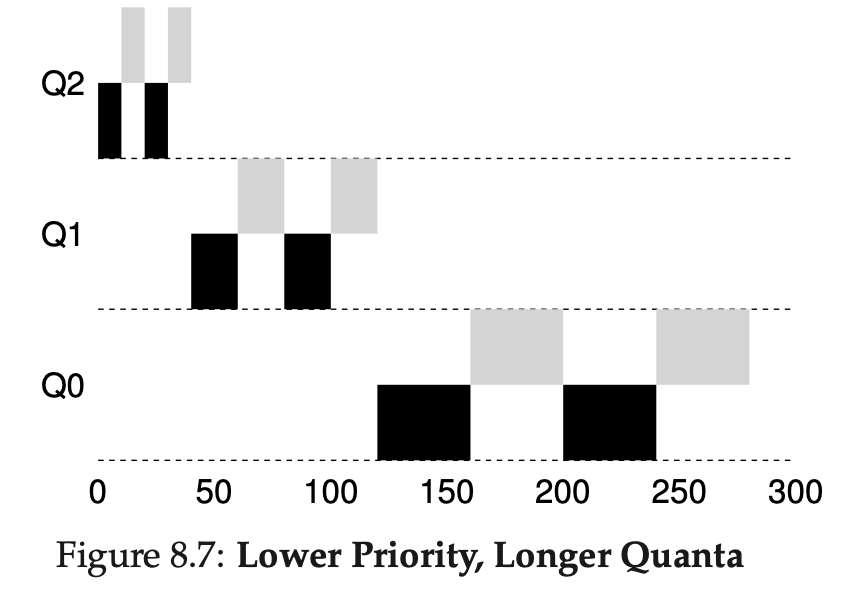
위의 예를 보게 되면 Q0, Q1, Q2의 time slice가 모두 다른 것을 볼 수 있습니다. 우선순위가 낮다는 말은 CPU를 주로 사용한다는 말이고 실행시간이 긴 작업들이 이에 속합니다. 따라서 time slice가 큰 것이 더 잘 작동할 수 있습니다. 이는 Context Switch와도 관계가 있습니다. Context Switch에도 비용이 발생하기 때문에 우선순위가 낮은 작업에서는 이를 최소화 하는것이 더 효율적일 수 있기 때문입니다. 반면에 우선 순위가 높은 작업은 주로 I/O를 사용하는 대화형 작업이며 짧은 time slice를 적용하여 빠르게 다음 작업을 수행하는 것이 좋습니다.
MLFQ에서 큐의 개수는 몇 개가 좋을까요? 실제 Solaris에서 사용하는 OS의 예를 보며 알아보겠습니다.

위의 그림에서 보면 큐 개수가 170개인 것을 볼 수 있습니다. 또한 각각의 우선순위에 접근할 수 있는 작업들의 종류를 구분해놓은 것을 볼 수 있습니다. 여기서 사용자 작업에 사용되는 큐들인 0~60번 큐 까지는 어떻게 우선순위를 설정하는지도 살펴보겠습니다.

음.. 글씨가 좀 못났지만 이해해주세요..ㅎㅎ
우선 time slice부터 살펴보겠습니다. 아까 말한 대로 우선순위가 낮을수록 time slice를 길게 설정한 것을 볼 수 있습니다. 그리고 이렇게 설정된 time slice를 모두 사용하면 우선순위를 내려줍니다. 반면에 time slice를 모두 사용하지 않았을 경우엔 저희는 우선순위를 그대로 유지한다라고 규칙을 정했었는데 solaris에서는 우선순위를 높여주는 규칙을 사용한 거 같습니다. 이 말은 I/O가 발생하면 우선순위를 높여주고 그렇지 않으면 우선순위를 낮춰준다고 이해할 수 있습니다.
MLFQ: Summary
이렇게 MLFQ에 대해 알아봤습니다. 이름이 왜 Multi Level Feedback Queue인지 이제는 알 수 있을 거 같습니다. 우선 여러 개의 큐가 존재하고 큐들은 각각 다른 레벨의 우선순위를 가지므로 multi level queue입니다. 그리고 과거의 수행 결과를 보고 우선순위를 변경해주는 식의 방법이므로 feedback이라는 단어도 추가됐습니다.
그럼 지금까지 규칙들을 마지막으로 정리해 보겠습니다.
- 규칙 1 : 우선순위가 높은 프로세스들을 먼저 수행한다.
- 규칙 2 : 작업들이 같은 우선순위를 갖는다면 RR로 수행한다.
- 규칙 3 : 새로운 프로세스가 시스템에 들어가면 가장 높은 우선순위를 부여한다.
- 규칙 4 : 작업은 모든 우선순위에서 주어진 time slice를 모두 사용하면 우선순위가 감소한다.
- 규칙 5 : 일정 시간 후 시스템의 모든 작업을 우선순위가 가장 높은 큐로 이동한다.
결국 MLFQ로 하고 싶었던 일은 batch 작업과 interactive 작업에 모두 좋은 성능을 가져오는 것이었습니다.
MLFQ에 대해 이해하시는데 도움이 되셨길 바라며 글을 마치도록 하겠습니다!
감사합니다.
다음 글 : 공평한 스케줄러 만드는 법
'Computer > Operating System' 카테고리의 다른 글
| [OS] 멀티 프로세서 스케줄링 - OS 공부 6 (0) | 2020.10.20 |
|---|---|
| [OS] 공평한 스케줄러 만드는 법 (Proportional Share) - OS 공부 5 (4) | 2020.10.18 |
| [OS] 프로세스를 스케줄링 하는 방법들 (Scheduling) - OS 공부 3 (0) | 2020.10.16 |
| [OS] Limited Direct Execution 메커니즘이란? - OS 공부 2 (2) | 2020.08.22 |
| [OS] 운영체제에서 Process란? - OS 공부 1 (1) | 2020.08.12 |
- Total
- Today
- Yesterday
- 문법
- 아이폰
- IOS
- BFS
- 스위프트
- 자료구조
- design
- 테이블뷰
- Swift
- OSTEP
- 앱개발
- System
- Combine
- 코딩테스트
- dfs
- pattern
- 백준
- 알고리즘
- Xcode
- operator
- 프로그래밍
- Publisher
- 코테
- document
- Apple
- DP
- mac
- operating
- 동시성
- OS
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |